Ist die neue Perl-Kolumne schon auf der Website des Linux-Magazins? Kann Amazon das neue Buch endlich liefern? Hat ein Anbieter den Preis für den CD-Brenner gesenkt? Der übers Web konfigurierbare Webseitenüberwacher schlägt Alarm, falls sich etwas rührt auf dem Web.
Bei O'Reilly soll demnächst "Writing Apache Modules with Perl and C" erscheinen. Um den Zeitpunkt, an dem Amazon den Schinken liefern kann, genau abzupassen, könnte ich jeden Tag die entsprechende Webseite anklicken -- aber dazu bin ich zu faul. Ein Perl-Skript zu schreiben, das eine Webseite vom Netz holt, ist ungefähr so schwer wie das "Hello World" in C und so liegt der Gedanke nahe, jede Nacht ein Skript mit Gedächtnis laufen zu lassen, das eine Reihe von Webseiten abklappert und feststellt, ob sich etwas darauf verändert hat. Ist dem so, verschickt es eine informative Email. Da viele Seiten Datumsangaben oder Session-Variablen in den HTML-Text schmuggeln, soll mittels eines regulären Ausdrucks festgestellt werden, ob sich ein bestimmter Ausschnitt der Seite gegenüber dem letzten Aufruf verändert hat.
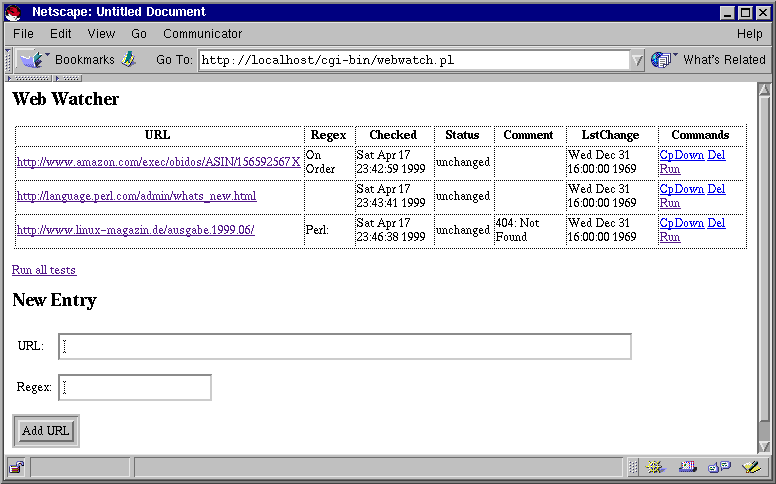
Das vorgestellte CGI-Skript webwatch.pl zeigt eine
Oberfläche nach Abbildung 1, über die der Benutzer URLs registrieren
kann.
Vier Fälle sind vorstellbar:
Eine Seite existiert noch nicht, wie zum Beispiel die der nächsten Ausgabe einer Zeitschrift. Der Zugriff auf den URL verursacht einen Fehler (z.B. 404: File not found). Erscheint die Seite eines Tages, soll der Alarm losgehen. Zu registrieren: Nur der URL, der reguläre Ausdruck kann entfallen.
Eine Seite enthält einen Textstring, auf dessen Verschwinden gewartet wird, z.B. steht auf den Beschreibungsseiten von Büchern, die von Amazon noch nicht lieferbar sind, 'Not Yet'. Ist das Buch vorrätig, verschwindet der String und das Skript schlägt Alarm. Zu registrieren: Der URL und als regulärer Ausdruck der String, der verschwinden soll.
Man wartet auf generelle Veränderungen auf einer Seite -- z.B. neue
Einträge auf der Seite mit den Perl-Neuigkeiten. Kommen neue Nachrichten
hinzu, schlägt das Skript an. Zu registrieren: Der URL und, optional,
ein regulärer Ausdruck, der einen bestimmten Seitenbereich abdeckt
(wie z.B. <TABLE>.*?</TABLE> für den Inhalt der
ersten im HTML vorkommenden Tabelle). Bei weggelassenem Regex
wird die gesamte Seite überwacht.
| |
| Abb.1: Der Web-Kontrolleur in Aktion |
Um webwatch.pl einen URL zur Überwachung anzubieten, trägt
man denselben einfach in das Textfeld (Abb. 1 unten) ein und fügt optional
noch ein regulären Ausdruck hinzu. Ein Druck auf den Add URL-Knopf,
und schon übernimmt webauth.pl die Aufgabe.
Abbildung 1 zeigt drei registrierte URLs:
Der erste ist der des vorher erwähnten Apache-Buches, als regulärer
Ausdruck steht dort On Order. So zeigt die Amazon-Seite
gegenwärtig On Order an, und dies ist genau der String, den das
Skript aus der Seite -- mit Erfolg -- extrahiert. Schlägt dies eines Tages
fehl, ist das Buch offensichtlich lieferbar und es geht eine Email an die
in webwatch.pl fest verdrahtete Adresse.
Der zweite URL ist der der Perl-Nachrichten. Da kein regulärer Ausdruck
angegeben wurde, schnappt sich webauth.pl bei jedem Test die ganze Seite
und speichert das Ergebnis. Ändert sich auch nur eine Kleinigkeit,
geht der Alarm los und eine Mail nach Abbildung 2 geht raus.
 |
| Abb.2: Die Alarm-Email |
Der dritte URL sucht nach der Juni-Ausgabe des Linux-Magazins, und während ich diesen Artikel schreibe, kann Tom ihn noch nicht draufgespielt haben, also liefert der Zugriff einen 404-Fehler. Dem Skript ist das egal, es 'merkt' sich, daß ein Fehler vorliegt, und führt den Test jeden Tag aufs neue durch, bis es eines Tages die Seite findet, und wegen des ausbleibenden Fehlers eine Alarm-Email losschickt.
Das Gedächtnis von webwatch.pl implementiert das Storable-Modul,
das die wohl simpelste Schnittstelle aller Persistenz-Bibliotheken
hat:
store($ref, $dbfile);
speichert die Referenz $ref und alles was darunterhängt rekursiv
in der Datenbankdatei $dbfile ab, andererseits zaubert
$ref = retrieve($dbfile);
die zwischenzeitlich auf Platte ausgelagerten Daten wieder hervor. In
webwatch.pl ist $ref die Referenz auf eine Liste @STORE,
die für jeden gespeicherten URL einen Hash enthält, der die
Felder
url URL
rgx Regulärer Ausdruck
id Eindeutige ID des Eintrags
status Changed/Unchanged
checked Zeitpunkt der letzten Prüfung
comment Fehlermeldungen
error Fehlercode
lstchange Letzte festgestellte Änderung der Seite
diff diff-Ausgabe der Änderung
match Gefundener String (Regex-Match oder ganze Seite)
als Key-Value-Paare enthält. Das praktische am Storable-Modul
ist freilich, daß store($ref, $dbname) den ganzen Rattenschwanz
automatisch wegschreibt, egal wieviel Einträge tatsächlich
darunterhängen.
Zeile 3 zieht das Algorithm::Diff-Modul, das eine schöne, dem
diff-Programm ähnliche Ausgabe der Unterschiede zweier Strings
erlaubt, der Abschnitt Installation zeigt, woher man es bekommt.
Storable erledigt, wie erwähnt, das Abspeichern und Wiederladen
von Daten, LWP::UserAgent zeichnet für die Web-Zugriffe verantwortlich
und HTML::Entities hat bloß ein eine praktische Funktion
namens encode_entities, die <>& zu <>&
maskiert damit's nicht im ausgegebenen HTML rappelt, falls Sonderzeichen
drin sind -- Zeile 16 definiert mit enc sogar noch eine Abkürzung darauf.
CGI ist Lincoln Steins praktisches CGI-Modul. Der -noDebug-Schalter,
der ab Version 2.38 enthalten ist, erlaubt den Aufruf des Skripts
auch von der Kommandozeile aus, ohne daß webwatch.pl, wie sonst
üblich, auf
die Eingabe der CGI-Parametern von der Konsole wartet -- schließlich soll
das Skript ja auch als Cronjob laufen.
CGI::Carp erlaubt
es, Fehlermeldungen des Skripts im Browser anzuzeigen, das ist
besonders zum Testen sehr handlich.
Die Zeilen 10-12 müssen den lokalen Gegebenheiten angepaßt werden, im Abschnitt Installation steht, wie man den Pfad für die Datenbankdatei wählt und die Email-Adresse anpaßt.
14 und 15 definieren nur HTML-Darstellungen der Changed/unchanged-Anzeige, damit's ins Auge sticht, ist Changed in Rot.
Die Zeilen 27 bis 57 handeln die verschiedenen CGI-Fälle ab:
new Neuen Record einfügen (url, regex)
del Record aus der Tabelle löschen (id)
upd Bestehenden Record verändern (id, url, regex)
run Testfall ablaufen lassen (id)
cpdown URL/Regex-Daten eines Records in
die Editierfelder kopieren (id)
runall Alle Testfälle laufen lassen ()
Der
erste if-Block ist gar kein CGI-Fall, denn die Environment-Variable
REMOTE_ADDR ist nur dann nicht gesetzt, falls das Skript von der
Kommandozeile aufgerufen wurde -- dies wird später der Cronjob tun.
In diesem Fall wird webwatch.pl alle Testfälle ausführen, die
Ergebnisse auf die Festplatte schreiben und wortlos zurückkehren.
Ähnlich wie im
nächsten CGI-Fall, der ausgeführt wird, falls der Parameter
runall gesetzt ist, und auch alle URLs überprüft, aber nicht
abbricht, sondern nach den if-else-Bedingungen das Bild nach
Abbildung 1 zum Browser schickt.
Im new-Fall hat der Benutzer den Add URL-Knopf gedrückt und
(hoffentlich) einen URL und (optional) einen regulären Ausdruck
in die Textfelder eingetragen. Das Skript hängt daraufhin einfach
einen neuen Eintrag an @STORE an und übernimmt die übergebenen
Parameter. Außerdem erzeugt es aus Uhrzeit (time) und Prozeßnummer
($$) eine eindeutige ID, die es dem Skript später erlaubt, einen
Record eindeutig zu referenzieren.
Der del-Fall löscht einen Record, dessen ID festliegt, der upd-Fall
setzt URL und Regex eines bestehenden Records neu. run läßt einen über
die ID festgelegten Testfall laufen. In allen Fällen sucht zunächst
ein grep-Befehl den Record mit der richtigen ID heraus, dessen
Referenz anschließend in $r abgelegt wird. Der Zugriff auf die
Recordfelder ist dann einfach über $r->{url} etc. möglich.
Ein kleiner Hack ist der cpdown-Fall: Klickt der Anwender
auf den CpDown-Link eines Records, soll
das Skript die URL und den Regex eines ausgewählten Records in
der im Browser dargestellten Liste in die Eingabefelder unten
kopieren, damit man sie mit dem Update-Knopf aktualisieren kann.
Das spart eine Extra-Seite in dem eh nicht gerade kurzen Skript.
Die Zeilen 61 bis 85 erzeugen den HTML-Code, der die gespeicherten URLs
samt den
zugehörigen Meßergebnissen anzeigt. Wie Abbildung 1 zeigt, malt
das Skript für jeden Record in die letzte Spalte der Tabelle drei
Links, CpDown, Del und Run. Die url-Funktion aus dem
CGI-Modul liefert hierzu den URL, mit dem webwatch.pl aufgerufen
wurde und die CGI-Parameter cpdown, del und run
hängt es einfach nach der GET-Methode
hintendran. Neben der gewählten Aktion wird auch die ID des Records
mitgegeben, damit webwatch.pl auch weiß, welcher Record
gemeint ist.
Die Zeilen 88-89 schreiben dann am Ende der Tabelle
noch schnell einen Link, der die
runall-Methode anfordert, damit man nicht nur von der Kommandozeile,
sondern auch vom Browser aus alle Testfälle auf einmal durchrasseln kann,
aber im Normalfall sollte diese Aufgabe ein Cronjob übernehmen.
In den Zeilen 92-112 entstehen die Eingabefelder für den URL und
den Regex einschließlich des Submit-Knopfes, und, falls es etwas zum
Auffrischen gibt (d.h. im upd oder cpdown-Fall),
kommt noch einen Update-Knopf hinzu.
Zeile 104 schmuggelt den ID-Parameter in ein verstecktes Feld, falls
das Skript damit aufgerufen wurde.
Zeile 114 schließlich speichert den Daten-Baum in der Datenbank-Datei ab.
Die Hilfsfunktion page_snippet, die in den Zeilen
118-135 definiert ist, nimmt einen URL und einen optionalen Regex entgegen,
holt das entsprechende Dokument vom Netz und versucht, dessen Inhalt mit
dem Regex zur Deckung zu bringen. Der abgedeckte Text, der nach den
Regex-Regeln in der Variablen $& liegt, wird zurückgereicht. Falls
kein Regex angegeben wurde, kommt der gesamte Text des Dokuments zurück.
Eine weitere Hilfsfunktion ist mkdiff, die den Unterschied zwischen
zwei hereingereichten Strings im diff-Format ausspuckt. Sie wird später
genutzt, um in den ausgesandten Emails darzulegen, was sich denn nun
genau am Dokument geändert hat. mkdiff
ist ein schamlos abgekupfertes Testbeispiel aus der
Algorithm::Diff-Distribution.
Die email-Funktion ab Zeile 164 bastelt aus den Feldern eines Records,
dessen Dokument sich geändert hat, eine Mail und schickt sie an
den Empfänger der in EMAIL_TO in Zeile 11 festgelegt wurde. Der
Einfachheit halber nutzt sie einfach den Sendmail-Daemon, der auf
den meisten Linux-Systemen konfiguriert sein sollte.
run_test ab Zeile 187 läßt einen Test laufen, dessen Record
hereingereicht wurde. Es ruft die page_snippet-Funktion auf,
die im Gutfall einen String (den erkannten Bereich) und im Fehlerfall
eine Referenz auf einen Array zurückgibt, der als Elemente
den HTTP-Errorcode und eine leserliche Meldung enthält. Die
ref-Funktion in Zeile 201 prüft diesen Fall, denn sie gibt für einen
String einen falschen Wert zurück und für eine Array-Referenz
den String "ARRAY".
Anschließend prüft run_test die eingangs dieses Artikels beschriebenen
Fälle, und je nach dem, wie sich ein Dokument verändert hat, setzt es
die Record-Felder status, comment und Konsorten.
Damit in der Tabelle keine häßlichen Löcher
entstehen, wenn mal ein Eintrag leerbleibt, werden manche Felder statt
auf "" auf " " gesetzt, ein non-blank-space in HTML.
Gibt page_snippet den Wert 0 zurück, hat der reguläre Ausdruck
nicht gegriffen und im Kommentarfeld wird deswegen No Match abgelegt.
Zu Anfang steht in $r->{error} noch der Fehlercode des letzten
Aufrufs, falls etwas schiefgelaufen ist. Dieser Wert wird zunächst
in $last_time_error gesichert, denn run_test muß den Fehlercode
entsprechend des Ergebnisses des aktuellen Tests setzen.
Ein frisch eingetragener URL, der noch nie getested wurde, hat
wegen Zeile 38 den Status
"?" und run_test sorgt dafür, daß nicht beim ersten Mal
-- egal ob der Zugriff schiefgelaufen ist oder erfolgreich war --
gleich der Alarm losgeht, schließlich muß sich erst etwas verändern.
Als erstes muß webwatch.pl ins cgi-bin-Verzeichnis des Webservers.
Drei Parameter in den Zeilen 10-12 harren der Anpassung: $DB gibt die
Datei an, in der das Skript die Daten zwischen den Aufrufen ablegt,
$EMAIL_TO ist die Email-Alarm-Adresse und $EMAIL_FROM sollte
der Absender der Email, also WebWatcher sein.
Wichtig ist, daß die Rechte des Benutzers, unter dem der Webserver
läuft (meistens nobody), es dem Skript erlauben,
die $DB-Datei zu beschreiben. webauth.pl
legt die Datei beim ersten Aufruf selbständig an,
jedoch muß das angegebene Verzeichnis beschreibbar sein, sonst
meldet webwatch.pl einen Fehler. Am einfachsten startet man
webwatch.pl einmal von der Kommandozeile, läßt es seine
Datenbankdatei anlegen, und ändert dann deren Rechte auf 666.
Um das Skript täglich mittels eines Cronjobs zu starten, ist zu beachten, daß dieser unter Umständen unter anderen Benutzerrechten läuft. Eine einmal angelegte Datenbank-Datei läßt sich zu diesem Zweck einfach mit
chmod 666 /pfad/zur/db/datei
allgemein beschreibbar machen.
Das Storable-Modul liegt modernen Perl-Versionen bereits bei,
auch LWP::UserAgent und CGI sind alte Bekannte.
Den Diff-Algorithmus gibt's unter
CPAN/modules/by-authors/id/MJD/Algorithm-Diff-0.59.tar.gz
auf dem CPAN, zur Drucklegung klappte die Installation der
Algorithm/Diff.pm-Datei noch nicht, sie läßt sich aber
sehr leicht von Hand an Ort und Stelle kopieren.
Der täglich ablaufende Cronjob wird mit crontab -e folgendermaßen
eingetragen:
30 0 * * * /home/mschilli/scripts/webwatch.pl
Eigentlich dürfen sich der Cronjob und das CGI-Skript beim
Laden und Speichern der Datenbankdatei nicht in die Quere kommen,
wer will, kann die Datei noch mit flock sichern.
So laufen täglich um 00:30 alle Testfälle der Reihe nach durch -- und am nächsten Morgen warten die heißesten Neuigkeiten schon in der Mailbox des glücklichen Anwenders. Alles unter Kontrolle!
001 #!/usr/bin/perl -w
002 ##################################################
003 # Michael Schilli, 1999 (mschilli@perlmeister.com)
004 ##################################################
005
006 use Algorithm::Diff qw/diff/;
007 use LWP::UserAgent;
008 use Storable;
009 use HTML::Entities;
010 use CGI 2.38 qw/:standard/;
011 use CGI::Carp qw/fatalsToBrowser/;
012
013 my $DB = "/tmp/controlletti.dat";
014 my $EMAIL_TO = "bgates\@microsoft.com";
015 my $EMAIL_FROM = "webwatch\@host.com";
016
017 my $CHANGED = "<font color=red>CHANGED</font>";
018 my $UNCHANGED = "unchanged";
019
020 sub esc { encode_entities($_[0]); };
021
022 if (-r $DB) {
023 my $store = retrieve($DB) ||
024 die("$DB: Cannot restore");
025 @STORE = @$store;
026 } else {
027 @STORE = ();
028 }
029
030 if(!$ENV{'REMOTE_ADDR'}) { # Command line call
031 foreach $r (@STORE) { run_test($r); }
032 store(\@STORE, $DB) || die "Store $DB failed";
033 exit(0);
034
035 } elsif(param('runall')) { # Run all tests
036 foreach $r (@STORE) { run_test($r); }
037
038 } elsif(param('new')) { # Insert new record
039 push(@STORE,
040 {url => param('url'), rgx => param('rgx'),
041 status => '?', id => time . $$});
042
043 } elsif(param('del')) { # Delete record
044 @STORE = grep { $_->{id} != param('id') } @STORE;
045
046 } elsif(param('upd')) { # Update record
047 ($r) = grep { $_->{id} == param('id') } @STORE;
048 $r->{url} = param('url');
049 $r->{rgx} = param('rgx');
050
051 } elsif(param('run')) { # Run test now
052 ($r) = grep { $_->{id} == param('id') } @STORE;
053 run_test($r);
054
055 } elsif(param('cpdown') || param('id')) {
056 # Copy record to edit fields
057 ($r) = grep { $_->{id} == param('id') } @STORE;
058 param('url', $r->{url});
059 param('rgx', $r->{rgx});
060 }
061
062
063 # Display list
064 print header(), start_html(-BGCOLOR => 'white'),
065 h1("Web Watcher"), "<TABLE>";
066 print "<TABLE BORDER=1>",
067 TR(map { th($_) } qw/URL Regex Checked
068 Status Comment LstChange Commands/);
069 foreach $r (@STORE) {
070 my $chktime = $r->{checked} ?
071 scalar localtime($r->{checked}) :
072 "Not Yet";
073 print TR(
074 td(a({href => $r->{url}}, $r->{url})),
075 td(esc($r->{rgx}) || " "),
076 td($chktime),
077 td($r->{status}),
078 td($r->{comment}),
079 td(scalar localtime $r->{lstchange}),
080 td(a({href => url() . "?cpdown=1&id=$r->{id}"},
081 "CpDown"), " ",
082 a({href => url() . "?del=1&id=$r->{id}"},
083 "Del"), " ",
084 a({href => url() . "?run=1&id=$r->{id}"},
085 "Run"), " ",
086 ));
087 }
088 print "</TABLE>";
089
090 # Link for running all tests
091 print p, a({href => url() . "?runall=1"},
092 "Run all tests");
093
094 # Form for new entries
095 print h2("New Entry"), start_form(),
096 table(
097 TR(td("URL:"),
098 td(textfield(-size => 80, -name => 'url'))),
099 TR(td("Regex:"),
100 td(textfield(-name => 'rgx'))),
101 ),
102 submit(-name => 'new',
103 -value => 'Add URL');
104
105 # Hidden ID field in case it's there
106 if(param('id')) {
107 print hidden(-name => 'id',
108 -value => param('id')),
109 }
110 if(param('upd') || param('cpdown')) {
111 print submit(-name => 'upd',
112 -value => 'Update');
113 }
114
115 print end_form(), end_html();
116
117 store(\@STORE, $DB) || die "Store to $DB failed";
118
119
120 ##################################################
121 sub page_snippet {
122 ##################################################
123 my ($url, $rgx) = @_;
124
125 my $req = HTTP::Request->new('GET', $url);
126 my $resp = LWP::UserAgent->new->request($req);
127
128 if($resp->is_error()) {
129 return [$resp->code, $resp->message];
130 }
131
132 if($rgx) {
133 $resp->content() =~ /$rgx/si || return 0;
134 return $&;
135 }
136
137 return $resp->content();
138 }
139
140
141 ##################################################
142 sub mkdiff {
143 ##################################################
144 my ($t1, $t2) = @_;
145 my $r = "";
146
147 my $diffs = diff([split(/\n/, $t1)],
148 [split(/\n/, $t2)]);
149
150 return "" unless @$diffs;
151
152 foreach $chunk (@$diffs) {
153 foreach $line (@$chunk) {
154 my ($sign, $nu, $text) = @$line;
155 $r .= sprintf("%4d$sign %s\n", $nu+1, $text);
156 }
157 $r .= "-------------";
158 }
159
160 return($r);
161 }
162
163
164 ##################################################
165 # alert by email
166 ##################################################
167 sub email {
168 my ($r) = @_;
169 my $days = $diff = "";
170
171 my $text = <<EOT;
172 Dear Webwatch Subscriber,\n
173 the content of the following URL has changed:\n
174 $r->{url}\n\nA diff to the previous content reads:
175 \n$r->{diff}\n\nGreetings from Planet Perl!\n\n
176 Your humble WebWatch program.
177 EOT
178
179 open(PIPE, "| /usr/lib/sendmail -t") ||
180 die("Cannot connect to sendmail");
181 print PIPE "From: $EMAIL_FROM\n";
182 print PIPE "To: $EMAIL_TO\n";
183 print PIPE "Subject: WebWatch Alert\n\n";
184 print PIPE "$text\n.\n";
185 close(PIPE) || die "Sendmail failed";
186 }
187
188
189 ##################################################
190 sub run_test {
191 ##################################################
192 my $r = shift;
193
194 my $match = page_snippet($r->{url}, $r->{rgx});
195 my $last_time_error = $r->{error};
196
197 $r->{comment} = $match ? " " : "No match";
198 $r->{error} = "";
199 $r->{checked} = time;
200
201 if(ref($match)) {
202 # There's an error
203 $r->{error} = $match->[0];
204 $r->{comment} = "$match->[0]: $match->[1]";
205 $r->{diff} = "Error: $r->{comment}";
206 if($last_time_error eq $match->[0] ||
207 $r->{status} eq "?") {
208 # Same error as last time or first time call
209 $r->{status} = $UNCHANGED;
210 } else {
211 #
212 $r->{status} = $CHANGED;
213 email($r);
214 }
215 return;
216 }
217
218 if($last_time_error) {
219 $r->{status} = $CHANGED;
220 $r->{lstchange} = time;
221 $r->{match} = $match;
222 $r->{diff} = "Recovered from $last_time_error";
223 email($r);
224 } elsif($r->{match} eq $match) {
225 $r->{status} = $UNCHANGED;
226 } else {
227 if($r->{status} eq '?') {
228 $r->{status} = $UNCHANGED;
229 $r->{match} = $match;
230 return;
231 } else {
232 $r->{status} = $CHANGED;
233 }
234 $r->{lstchange} = time;
235 $r->{diff} = mkdiff($r->{match}, $match);
236 $r->{match} = $match;
237 email($r);
238 }
239
240 return;
241 }
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |