Schon länger als zwei Jahre läuft der Perl-Snapshot -- Zeit für eine Suchmaschine, die zu Stichworten die passenden Artikel liefert.
War da nicht schon einmal ein Perl-Snapshot, der sich um Suchmaschinen drehte? Letztes Jahr? Noch länger her? Mit den heute vorgestellten Skripts gehört verzweifeltes Suchen und Haareraufen der Vergangenheit an, denn wie die großen Suchmotoren Altavista, Hotbot oder deja.com nimmt unser Maschinchen Stichworte entgegen, durchkämmt einen automatisch angelegten Index und spuckt die URLs passender Snapshot-Artikel aus, auf die man nur zu klicken braucht, um das Gewünschte genau nachzulesen.
Der heute vorgestellte Search-Engine Glimpse ist frei erhältlich
(siehe Installation)
und bietet ein denkbar einfaches Interface zum Aufbau eines Such-Features:
Ein Programm glimpseindex durchstöbert einen Verzeichnisbaum
treedir
auf der Festplatte und legt einen aus mehreren Dateien bestehenden
Index im Verzeichnis indexdir an:
glimpseindex -H indexdir treedir
Anschließend fördert das zweite Programm in der Sammlung, glimpse,
aufs Stichwort passende Einträge zutage:
glimpse -y -L 100 -i -W -H indexdir search_term
Die Option -y hält glimpse davon ab, lästige Zwischenfragen
zu stellen (wie z.B. ``Wollen Sie wirklich den gesamten Index durchsuchen?''),
denn schließlich soll das Kommando auf einem Webserver laufen, der keinerlei
Verständnis für Geschwätzigkeit aufbringt. -L gibt die maximale
Anzahl zurückgelieferter Einträge an. -i ignoriert Groß-
und Kleinschreibung. Mit -W bezieht glimpse
logische Verknüpfungen (z.B. AND) im Suchbegriff auf die gesamte Datei
und nicht nur auf eine Zeile. -H gibt die Lage des Indexverzeichnisses
an und der search_term kann entweder
Biermann)
eine UND-Verknüpfung aus mehreren Worten, getrennt durch den Semikolon
(z.B. Cookie;Lincoln)
eine ODER-Verknüpfung mehrerer Worte, getrennt durch ein Komma
(z.B. Tom,Hugo)
sein. Wildcards und sogar phonetische Übereinstimmungen etc. werden
unterstützt, wie man auf der Manualseite von glimpse nachlesen kann.
Die Ausgabe von glimpse ist eine Liste im Format
Pfad/Dateiname: Gefundener Text
Nun liegen aber die Artikel des Linux-Magazins nicht direkt
auf perlmeister.com,
dort stehen nur Links auf die einzelnen Ausgaben des Linux-Magazins,
die wiederum ein Server anbietet, der wahrscheinlich in Toms feuchtem
Keller steht.
Das Skript mirror.pl schnappt sich alle URLs vom Netz, die
in einer Datei urls.txt aufgelistet sind.
Es legt pro URL jeweils eine lokale Kopie des Inhalts als HTML-Datei an,
die in
einer Verzeichnisstruktur liegt, an deren Spitze das Verzeichnis
für den Webserver steht, dann Unterverzeichnisse entsprechend der Pfadangabe
im URL und schließlich eine Datei, die nach dem
letzten Teil des URLs benannt ist.
Demnach wird das Ergebnis eines Requests für
http://server.com/path/datei.html
auf der Festplatte unter server.com/path/datei.html abgespeichert.
$LOCAL_TREE in mirror.pl definiert die absolute Lage des Baumes mit den
gespiegelten Seiten im Dateisystem.
Zeile 13 in Listing mirror.pl gibt die Textdatei an, die alle URLs von
relevanten Artikeln enthält.
Zeile 16 öffnet sie und Zeile 18 liest alle Zeilen
daraus in @URLS ein, sicherstellend, dass Kommentarzeilen,
die mit '#' beginnen und offensichtlich leere Zeilen ignoriert werden.
Zeile 19 entfernt noch das jeder Dateizeile anhaftende Newline-Zeichen
und ab diesem Zeitpunkt steht in @URLS eine Liste von URLs, die
auf Artikel verweisen.
Die Zeilen 22 bis 24 bilden das eigentliche Programm und versuchen,
den Inhalt jedes gefundenen URLs auf der lokalen Festplatte zu spiegeln.
Hierbei werden unter $LOCAL_TREE Unterverzeichnisse für einzelne
Server und deren Pfade angelegt. Die Funktion url2file, die ab
Zeile 29 definiert ist, legt fest, welche Dateien den Inhalt der URLs
widerspiegeln.
Die foreach-Schleife zwischen den Zeilen 22 und 24 ruft für jeden
URL aus url.txt die Funktion mirror_url auf, die den
Dokumenttext
vom Internet holt und auf der Festplatte unter $LOCAL_TREE
und dem Host-/Pfad-/Dateinamen abspeichert. mirror_url nutzt
den LWP::UserAgent, der mit der mirror-Methode Dateien nur
dann aus dem Internet überträgt, falls sie auf dem weit entfernten
Server in einer neueren Version vorliegen.
Zeile 46 nutzt die Funktion dirname, die aus dem Modul File::Basename
stammt, und, genau wie der Shell-Befehl dirname, den Verzeichnisanteil
aus einer Pfadbezeichnung extrahiert. Die Funktion mkpath wurde von
File::Path eingeschleppt und legt wie mkdir Verzeichnisse an,
nur dass sie in beliebige Tiefen vordringt. File::Spec fügt die
einzelnen Teile einer Pfadangabe betriebssystemunabhängig zu einem Pfad
zusammen -- in diesem Fall könnte man die Strings zwar einfach mit einem
"/" zusammenflicken, aber heute machen wir's mal sauber.
Die mirror-Methode
des LWP::UserAgents liefert ein Objekt vom Typ HTTP::Response
zurück, das man sehr einfach mit der is_error-Methode befragen
kann, ob der Zugriff erfolgreich war oder nicht. Falls der Server
antwortet, dass sich die Datei seit dem Datum, an die
lokale Kopie erstellt wurde, nicht verändert hat, findet kein
weiterer Transfer statt -- in der Theorie. In der Praxis sorgen
freilich Werbebanner für sich ständig ändernde Seiten.
mirror.pl muss einmal am Tag laufen, um die gespiegelten Dateien
mit den WWW-Dateien synchron zu halten, ein Cronjob mit dem Eintrag
00 14 * * * /home/mschilli/bin/mirror.pl 2>&1
ruft mirror.pl jeden Tag um zwei Uhr nachmittags auf.
Steht der lokale Spiegel einmal, genügt der Aufruf eines
Shell-Skripts nach Listing index.sh, um einen Index erzeugen,
mittels dessen später ein CGI-Skript sehr schnell herausfinden kann,
ob in irgendeiner Datei unterhalb einer definierten Hierarchie
ein bestimmtes Stichwort auftauchte. Auch index.sh muss in
den täglichen Cronjob.
Am komfortabelsten funktioniert dies natürlich über ein
CGI-Skript, das ein Suchfeld bereitstellt, in das man das Stichwort
über einen Browser eingibt, worauf das Skript mittels
glimpse die passenden lokalen Dateien herausfindet, diese zurück in
URLs verwandelt und als Ergebnisliste mit Links zum Linux-Magazin
anzeigt.
article-search.pl tut genau dies. Zeile 3 holt Lincoln Steins
praktisches CGI-Modul herein.
Zeile 4 bringt HTTP::Entities ins Spiel, ein Modul, das die Funktion
encode_entities bereitstellt, welche den HTML-Markup im Suchergebnis
so kodiert, dass
er wörtlich dargestellt wird und nicht das Browserbild
durcheinanderbringt.
HTML::FormatText und HTML::TreeBuilder dienen dazu,
die gefundenen Textsnippets,
die ja HTML-Markup enthalten, möglichst genau auf normalen Text abzubilden.
Die Zeilen 8 bis 11 in article-search.pl setzen den Shell-Pfad auf
das Verzeichnis, in dem
die glimpse-Programme residieren, außerdem das Verzeichnis für den
Index, den glimpseindex anlegt ($BASE_DIR), weiter
das Spiegelverzeichnis für
die Webdokumente ($LOCAL_TREE) und schließlich in Zeile 11
den String, der vor die relative
Pfadangabe
eines lokalen Dokuments gestellt werden muss, damit das Ganze wieder zum
Linux-Magazin und nicht auf die Festplatte zeigt.
Zeile 13 gibt den HTTP-Header aus, die Zeilen 15 bis 19 schreiben die
Überschrift mitsamt einem Formularfeld für einzugebende Stichworte
und einem Submit-Knopf. Sollte dies der erste Aufruf des Skripts
vom Webbrowser sein,
ist der Parameter s nicht gesetzt, und Zeile 21 beendet die Ausgabe.
Andernfalls liefert param("s") den String, den der Benutzer ins
Formularfeld eintrug und die Zeilen 26 bis 29 nehmen noch einige
Korrekturen vor. Die glimpse-Anforderung, eine UND-Verknüpfung
zweier Stichworte mit dem Zeichen ``;'' zu kodieren, ist ziemlich
unintuitiv und so ersetzt Zeile 27 Wortzwischenräume durch einen
einzigen Semikolon. Denn was der Benutzer mit dem Suchstring
Rache Biermann wahrscheinlich sucht, sind Dokumente, die beide
Wörter enthalten, mit Rache;Biermann kapiert's sogar glimpse.
Wird allerdings nach "Larry Wall" (mit doppelten
Anführungszeichen) gesucht, will der Benutzer wahrscheinlich den
vollen String sehen und nicht nach Dokumenten forschen, die irgendwo
verstreut beide Strings enthalten -- und so lässt Zeile 27
den Suchbegriff in diesem Fall unberührt.
Zeile 29 eliminiert noch Sonderzeichen. Dass wir Apostrophen entfernen, ist essentiell, andernfalls könnte ein bösmeinender Geselle uns Stichworte ins Formularfeld legen, die dem Aufruf über die Shell in Zeile 34 Befehle anfügten und dem Schurken erlauben würden, auf unserer Festplatte herumzuorgeln -- drei Kreuze!
Zeile 31 baut das Shell-Kommando zusammen, das in Zeile 34 startet
und dessen Ergebnis die while-Schleife ab Zeile 37 zeilenweise
einliest. Aus einer Datei macht Zeile 40 einen URL, indem es
-- dank unserer geschickten Pfadvergabe -- nur ein http:// davor
setzt.
Der HTML::TreeBuilder liest den HTML-Baum ein, den der Formatierer
anschließend als Klartext ausgibt. Wegen der kurzen Snippets
kann es natürlich passieren, dass der Wandler wegen abgeschnittener
Tags überfordert ist und HTML-Markup stehen ließ, und so sorgt
Zeile 44 dafür, dass dieser wenigstens HTML-kodiert wird und
nicht den Rendering-Engine des Browsers aus dem Konzept bringt.
Da glimpse mehrere Treffer in derselben Datei mit mehr als
einer Meldung anzeigt, kumuliert Zeile 45 die gefundenen
Textstücke auf Datei-Basis auf. Die foreach-Schleife ab
Zeile 48 gibt das Ergebnis zusammen mit korrekten Links
als HTML-Liste aus.
glimpse gibt's kostenlos -- unter http://glimpse.cs.arizona.edu.
Entweder als Source-Distribution unter
ftp://ftp.cs.arizona.edu/glimpse/glimpse-4.1.src.tar.gz
oder, für die ganz Faulen, als fertiges Binary für Linux unter
ftp://ftp.cs.arizona.edu/glimpse/glimpse-4.1-bin-Linux-2.0.30-i486.tar.gz
article-search.pl muss ins cgi-bin-Verzeichnis des
Webservers,
urls.txt wird mit interessanten URLs angefüllt,
mirror.pl angestoßen,
index.sh ausgeführt -- und fertig ist der Lack. Das
Ergebnis lässt sich unter
http://perlmeister.com/cgi/article-search.pl
ausprobieren. Fröhliches Stöbern!
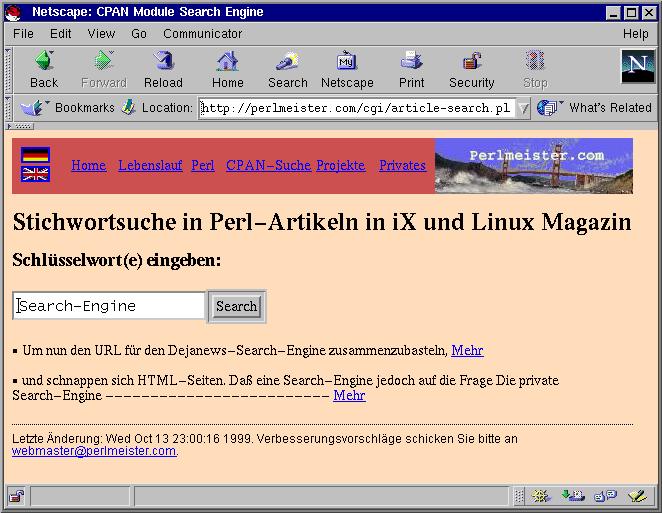
| |
| Abb.1: Such-Ergebnisse zum Stichwort "Search-Engine" |
01 #!/usr/bin/perl -w
02 ##################################################
03 # Mirror a number of URLs on a file system
04 # 1999, mschilli@perlmeister.com
05 ##################################################
06
07 use LWP::UserAgent;
08 use File::Basename;
09 use File::Path;
10 use File::Spec;
11
12 my $LOCAL_TREE = "/DATA/articles/LOCAL_TREE";
13 my $URLS_FILE = "/DATA/articles/urls.txt";
14
15 ### Read URLs from file, skip blanks and comments
16 open FILE, "<$URLS_FILE" or
17 die "Cannot open $URLS_FILE";
18 @URLS = grep { ! /^\s*(#|$)/ } <FILE>;
19 chomp @URLS;
20 close FILE;
21
22 foreach $url (@URLS) {
23 print mirror_url($url), "\n";
24 }
25
26 ##################################################
27 ### Transform a URL into a file name
28 ##################################################
29 sub url2file {
30 my $url = shift;
31 $url =~ s#.*://##g;
32 return File::Spec->catfile($LOCAL_TREE, $url);
33 }
34
35 ##################################################
36 ### Store content of a URL on disc if modified
37 ##################################################
38 sub mirror_url {
39 my $url = shift;
40 my $file = url2file($url);
41
42 my $ua = LWP::UserAgent->new();
43
44 print "Mirroring $url in $file\n";
45
46 my $dir = dirname($file);
47 mkpath($dir) unless -d $dir;
48
49 my $response = $ua->mirror($url, url2file($url));
50 if($response->is_error()) {
51 print "Failed to get $url: ",
52 $response->message(), "\n";
53 }
54 }
01 #!/usr/bin/perl -w
02
03 use CGI qw/:all/;
04 use HTML::Entities;
05 use HTML::FormatText;
06 use HTML::TreeBuilder;
07
08 $ENV{PATH} = "/usr/bin";
09 my $BASE_DIR = "/DATA/articles/glimpseindex";
10 my $LOCAL_TREE = "/DATA/articles/LOCAL_TREE";
11 my $HTTP_REP = "http://";;
12
13 print header();
14
15 print h1(center("Stichwortsuche in Perl-Artikeln")),
16 h3("Schlüsselwort(e) eingeben:"),
17 start_form(), textfield(-name => "s"),
18 submit(-name => "submit", -value => "Search"),
19 end_form();
20
21 exit 0 unless param("s");
22
23 $count = 0;
24 $search = param("s");
25
26 # Multiple search terms
27 $search =~ s/\s+/;/g unless $search =~ /"/;
28 # Delete leading/trailing blanks, '," and \
29 $search =~ s/^\s+|\s+$|['"\\]//g;
30
31 $command = "glimpse -y -L 100 -i -W " .
32 "-H $BASE_DIR '$search'";
33
34 open(PIPE, "$command |") or
35 die "Cannot open $command";
36
37 while(<PIPE>) {
38 my ($file, $text) = /(\S+):\s+(.*)/;
39 $count++;
40 $file =~ s#$LOCAL_TREE/#$HTTP_REP#g;
41 $formatter = HTML::FormatText->new();
42 $html = HTML::TreeBuilder->new->parse($text);
43 $text = $formatter->format($html);
44 $text = encode_entities($text);
45 $result{$file} .= $text;
46 }
47
48 foreach $url (keys %result) {
49 print li($result{$url},
50 a({href => $url}, "Mehr")), p();
51 }
52
53 close(PIPE) || die "$command failed";
54
55 print ul(i("Nichts gefunden.")) unless $count;
1
2 mkdir /DATA/articles/glimpseindex
3
4 glimpseindex -H /DATA/articles/glimpseindex \
5 /DATA/articles/LOCAL_TREE
6
7 chmod -R a+w /DATA/articles/glimpseindex
http://perlmeister.com/cgi/article-search.pl
http://www.linux-magazin.de/ausgabe.1997.11/Wais/wais.html
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |