Perls Version 5.6.0 bringt Unicode-Unterstützung, die nicht nur für Multibyte-Zeichen fernöstlicher Alphabete taugt, sondern sich sogar für Versionsnummern und IP-Adressen zweckentfremden lässt.
Am Anfang war nur Englisch im Computer. Eine Welt ohne Umlaute und ohne Probleme. Dann kamen lustige Schnörkel anderer westlicher Alphabete hinzu: Deutsche Umlaute, französische Accents, spanische Kopfüber-Fragezeichen, dänisches Smřrrebrřd und was des Schlingerkrams mehr ist. Als die Rechner leistungsfähiger wurden, zogen auch fernöstliche Alphabete ein. Die wiesen nicht nur einige Hände voll, sondern jeweils tausende von Zeichen auf.
Da der Computer keine Buchstaben versteht, sondern 'A' intern lieber als
0100.0001 (dezimal: 65) speichert, gibt es die ASCII-Tabelle, die
jedem gebräuchlichen Zeichen der Schriftsprache eine Nummer
zuordnet, die der Computer ohne Probleme im Speicher ablegt. Geht's
ans Ausgeben, sieht er schnell nach, wie das Zeichen 0100.0001 aussieht,
holt die Konturen von 'A' aus dem Speicher und stellt das Zeichen dar.
In der heilen Welt des Anfangs reichte eine Tabelle mit 128 Einträgen,
um Buchstaben, Zahlen und Sonderzeichen (unter ihnen auch undruckbare
Zeichen wie das Null-Byte oder die Terminal-Klingel)
jeweils einer Nummer zuzuordnen.
128 Einträge passen genau in sieben Bit, die sich binär
von 0000.0000 bis 0111.1111 durchnummerieren lassen.
Auf den Positionen 0 bis 31 stehen allerhand Sonderzeichen, unter ihnen
auch die Codes für den Zeilen- und Seitenvorschub. Ab Position 32
beginnt der druckbare Bereich, startend mit dem Leerzeichen, weiter über
das Alphabet in Groß- und Kleinschreibung und die Ziffern 0-9, bis
zu Interpunktionszeichen (;.,!?``'`)
und allerhand
Sonderzeichen wie ), < oder {.
Um das Byte
voll zu machen, ist üblicherweise die Norm ISO8859-1 (auch
Latin 1 genannt) dafür zuständig,
die Einträge 129 bis 256 (1000.0000 bis
1111.1111) mit europäischen Sonderzeichen aufzufüllen.
Das Skript ascii.pl gibt den ASCII-Zeichensatz mit den Latin-1-Erweiterungen
in Spalten von 32 Zeichen Länge aus. Es verwendet die
Perl-Funktion chr, die zu einer ASCII-Nummer das zugehörige
Zeichen ausgibt. Das POSIX-Modul stellt außerdem die Funktion
isprint bereit, die angibt, ob es sich um ein druckbares Zeichen
handelt oder nicht.
Diese Information nutzt ascii.pl dann, um entweder das Zeichen selbst
oder, statt eines undruckbaren Sonderzeichens, lieber ein Fragezeichen
auszugeben. Zur besseren Übersicht plaziert Zeile 7 am Ende jedes
32-Zeichen-Blocks noch einen Zeilenumbruch.
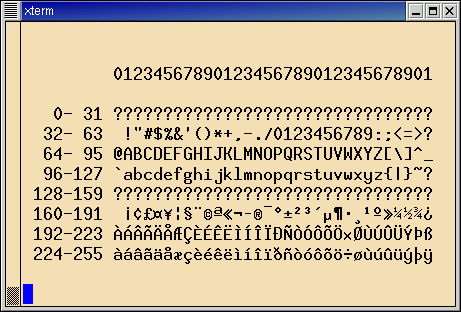
Abbildung 1 zeigt die von ascii.pl ausgegebene
ASCII-Tabelle mit eingefügten Zeilen- und Spaltennummern.
ascii.pl
1 #!/usr/bin/perl -w
2
3 use POSIX;
4
5 foreach (0..255) {
6 print isprint(chr $_) ? chr $_ : "?";
7 print "\n" if $_ % 32 == 31;
8 }
| |
| Abb.1: Die mittels eines Perl-Skripts ausgegebene ASCII-Tabelle |
Nun reichen, wie gesagt, 256 Einträge in der Tabelle bei weitem nicht für alle Sprachen dieser Welt. Die Unicode-Kodierung reserviert deswegen zwei Bytes pro Eintrag und erstellt eine Tabelle mit Zeichen, die von 0x0000 bis 0xFFFF durchnumeriert werden -- 65536 Einträge.
Sehr schön -- aber unpraktisch: die meisten Computertexte bleiben weiterhin in ASCII und hierfür zwei Byte pro Zeichen zu reservieren hieße unnützerweise doppelten Speicherplatz zu beanspruchen.
Hier kommt die UTF-8-Kodierung ins Spiel, die 7-Bit-ASCII-Daten (also die obere Hälfte von Abbildung 1) weiterhin mit jeweils einem Byte kodiert -- genau mit der jeweiligen ASCII-Nummer nämlich. Das erste Bit dieser Einträge ist immer Null.
Für die Unicode-Zeichen 128 bis 2047 hingegen
beansprucht UTF-8 jeweils zwei Bytes.
Der UTF-8-Standard kodiert jede der Zahlen in diesem Bereich
mit einer Bitfolge, die mit 110 anfängt und 16 Bits lang ist.
Das zusätzliche zweite Byte startet jeweils mit der Bitfolge 10.
So kann ein Programm, das eine beliebigen UTF-8 Bytefolge liest,
sofort entscheiden,
ob ein Byte ein ASCII-Zeichen beschreibt oder der Start oder die Fortsetzung
eines Multibyte-Zeichens ist. Es kann zu einem beliebigen
Zeitpunkt in einen UTF-8-Byte-Strom hereinschneien und dennoch den
Anfang des nächsten Zeichens herausfinden.
Den Unicode-Bereich von 2048 bis 65535 bildet UTF-8 dagegen mit
jeweils drei Bytes pro Zeichen ab. Jede der Dreier-Folgen beginnt
mit der Folge 1110, und die Folgebytes starten wiederum mit
10. Hier noch einmal die Kodierung im Überblick:
Unicode von bis Binärdaten
0000 007F 0xxx.xxxx
0080 07FF 110x.xxxx 10xxxxxx
0800 FFFF 1110.xxxx 10xxxxxx 10xxxxxx
Dies bedeutet aber, dass die Einträge 128 bis 255 in der Latin-1-Tabelle (Abbildung 1) nicht mit UTF-8 verträglich sind. Ein deutscher Text mit Umlauten ist nicht wie ein englischer gleichzeitig als ASCII und UTF-8 interpretierbar. Vielmehr müssen die Umlaute erst mit einem Konvertierungswerkzeug in 2-Byte-UTF-8 Codes umgewandelt werden, bis ein UTF-8-Parser sie begreift.
Listing a2u.pl zeigt ein Skript, das eine ASCII-Datei
entgegennimmt und sie in UTF-8 umwandelt. Als Testdatei
dient data.dat, die die folgende Zeile enthält:
Schöne Äpfel aus Überlingen.
Das Kommando
a2u.pl data.dat
packt sich data.dat, wandelt die
Umlaute in entsprechende UTF-8-Codes um, lässt aber sonst alles beim
Alten und schreibt die Datei wieder zurück.
a2u.pl
1 #!/usr/bin/perl -piw
2
3 no warnings utf8; # Warnungen aus (Bug)
4 tr/\80-\xff//CU; # Nach UTF-8 konvertieren
Wer sich ob des kompakten
Formats wundert, der sei auf die Schalter -p und -i in der
ersten Zeile verwiesen,
die perl automatisch einen In-Place-Edit aller auf der Kommandozeile
hereingereichten Dateien vornehmen lässt. Das Skript muss in diesem
Fall nur noch einen Ausdruck angeben, dem jede Zeile jeder Datei
unterworfen wird. Mit dem neuen Modifizierer CU für das gute
alte tr-Kommando lassen sich umzuwandelnde Zeichenbereiche angeben:
$string =~ tr/\x80-\xff//CU;
wandelt in $string alle ASCII-Codes größer gleich
128 in UTF-8 um. Im jetzt
erhältlichen perl 5.6.0 erzeugt diese Anweisung irrtümlich eine
Warnung, die a2u.pl vorläufig mit
no warnings utf8;
kalt stellt. Sieht man die umgewandelte Datei data.dat
nachher mit einem Editor an, zeigt sich ein Bild nach Abbildung 2.
Der verwendete vi gewinnt für die Darstellung zwar keinen
Schönheitspreis, lässt die Byte-Darstellung der ungewöhnlichen
Doppel-Zeichen aber intakt und erlaubt sogar vorsichtige Editierschritte.
 |
| Abb.2: Eine UTF-8-Datei mit dem Editor vi betrachtet. |
Für eine genauere Analyse der UTF-8-Zeichen kommt das Perl-Skript
binary.pl zum Einsatz. Es zeigt die Bytes einer Datei untereinander
im Binärformat an. Hierbei
achtet es auf die Muster am Byteanfang: 110, 1110
indizieren, dass es sich um spezielle UTF-8 Codes handelt.
Die Direktive no utf8 in binary.pl bewirkt,
dass perl alle analysierten Strings
byteweise behandelt. Gegenwärtig ist no utf8 zwar voreingestellt, doch
dies könnte sich in naher Zukunft ändern, wenn UTF-8 sich als
Standardkodierung für Perl-Skripts durchsetzt.
Das Kommando binary.pl data.dat gibt
01010011 01100011 01101000 11000011 10110110 01101110 ...
aus. Die ersten drei Bytes entsprechen ``S'', ``c'' und ``h'', das vierte
Zeichen, ein Doppelbyte, kodiert das ``ö'' von Schöne. Das fünfte
ausgegebene Byte kodiert das ``n'', der Rest der Ausgabe wurde weggelassen.
binary.pl hält in der Variable $follower fest, ob gerade ein
Ein-, Zwei- oder Dreibyte-Zeichen vorliegt
und weiss so, ob es nach dem Bytewert ein Leerzeichen oder
einen Zeilenumbruch ausgeben muss. Der <>-Operator in
Zeile 5 liest zeilenweise Daten ein, die entweder von auf der Kommandozeile
angegebenen Dateien oder von der Standardeingabe stammen. Der join-Befehl
steckt diese in einen Skalar $data, der alle Zeilen samt den
Umbrüchen enthält. Das split-Kommando mit dem Ausdruck //
schließlich teilt den String in seine Einzelbytes auf und legt
die Bytes als Einzelelemente im Array @bytes ab.
Die foreach-Schleife iteriert über alle Elemente und legt das
aktuelle Byte als ASCII-Zeichen in $byte ab. ord($byte) gibt
die zugehörige ASCII-Nummer zurück und der
Formatierer "%08b" des sprintf-Kommandos macht daraus einen
8 Zeichen langen Binärstring wie zum Beispiel 01010011.
binary.pl
01 #!/usr/bin/perl -w
02
03 no utf8; # Wichtig: Byteweise interpretieren!
04
05 my $data = join '', <>;
06 my $follower = 0; # Folge-Byte-Indikator
07
08 # $data in Einzelbytes aufteilen
09 my @bytes = split //, $data;
10
11 foreach $byte (@bytes) {
12 $bstring = sprintf "%08b", ord($byte);
13
14 # Folgen ein oder zwei Folgebytes?
15 $follower = 1 if $bstring =~ /^110/;
16 $follower = 2 if $bstring =~ /^1110/;
17
18 print $bstring, $follower ? " " : "\n";
19
20 $follower-- if $follower;
21 }
Die Rückwandlung von UTF-8 nach ASCII erledigt das Skript
u2a.pl -- soweit das UTF-8-Zeichen ein Pendant in der Latin-1-Tabelle
hat. Der Perl-Befehl
$string =~ tr/\x80-\xff//UC;
unterwirft die Zeichen des Strings $string der
Transformation.
u2a.pl
1 #!/usr/bin/perl -piw
2
3 tr/\0-\xff//UC; # Von UTF-8 nach Latin-1 wandeln
Um nun einem Skript mitzuteilen, dass es seine Daten nach dem neuen
Verfahren zeichen- (also eventuell multi-byteweise) und nicht
byteweise verarbeiten soll, dient das neue Pragma use utf8.
Die Direktive
use bytes hingegen bewirkt das Gegenteil, besteht also auf
traditionell byteweise interpretierten Daten. Der Kompatibilität
wegen ist momentan noch use bytes voreingestellt, man muss aber damit
rechnen, dass eines Tages UTF-8 zum Standard wird und perl byteweise
Datenbearbeitung nur noch mit explizitem use bytes anbietet.
Ganz in der Pragma-Tradition bewirken no utf8 beziehungsweise
no bytes das genaue Gegenteil ihrer use-Pendants.
Listing bytes.pl illustriert die Funktionsweise der
use utf8 bzw. no utf8 Direktiven. Im ersten Fall interpretiert
perl seine Strings zeichenweise -- wobei ein Zeichen auch mehrere
Bytes in UTF-8-Kodierung umfassen kann. Bei no utf8 (oder
wahlweise use bytes) hingegen ackert perl byteweise durch
Strings, ohne auf irgendwelche Sonderbytes zu achten. bytes.pl
nimmt auf der Kommandozeile den Namen einer oder mehrerer Dateien
entgegen und zählt einmal die enthaltenen UTF-8-Zeichen und einmal
die Anzahl der Bytes.
bytes.pl
01 #!/usr/bin/perl -w
02
03 $data = join '', <>;
04
05 # Zeichenweise zählen
06
07 use utf8;
08 @chars = split //, $data;
09 print "$#chars Zeichen\n";
10
11 # Byteweise zählen
12
13 no utf8;
14 @bytes = split //, $data;
15 print "$#bytes Bytes\n";
Zeile 3 liest alle einströmenden Daten in den
Skalar $data ein, der zunächst, bei eingeschaltetem use utf8,
zeichenweise interpretiert wird:
@chars = split //, $data;
erzeugt aus dem Skalar $data
einen Array @chars, der als Elemente alle
Zeichen von $data enthält. $#chars ist die Länge dieses Arrays,
die bytes.pl kurz darauf ausgibt. Die in Zeile 6 folgende
Direktive no utf8 weist perl hingegen an, den gleichen String
$data nicht zeichen- sondern nun byteweise zu interpretieren. Das folgende
@bytes = split //, $data;
erzeugt den Array @bytes, der die Bytes des Skalars als Elemente enthält.
Die Ausgabe sollte nach dem bisher gelernten nicht mehr verblüffen:
29 Zeichen
32 Bytes
Der Text enthält mit ö, Ä und Ü drei Sonderzeichen aus dem
oberen Teil der ASCII-Tabelle, die als jeweils ein Zeichen zählen,
aber jeweils zwei Bytes lang sind -- deswegen der Unterschied
von drei Bytes zwischen beiden Zählungen.
Hat man gerade keine japanische Tastatur zur Hand, muss aber eine
japanische Fehlermeldung schreiben, gestattet es Perl,
Strings mit hexadezimalen Unicode-Nummern im Format
"\x{HEXCODE}" aufzufüllen.
``Willkommen bei Linux'' heisst auf japanisch, wie mir meine
japanische Kollegin Rika bei Netscape versichert hat,
"Linux\x{3078}\x{3088}\x{3046}\x{3053}\x{305D}"
Ein CGI-Skript wie uni.pl bläst den String im UTF-8-Format raus
und erzeugt in einem Browser wie z.B. dem Netscape 6 für Linux,
der dieses Format versteht, ein Bild nach Abbildung 3.
uni.pl
1 #!/usr/bin/perl -w
2
3 use CGI qw(:all);
4 print header(-charset => 'utf-8');
5 # "Willkommen bei Linux" auf japanisch
6 print "Linux\x{3078}\x{3088}\x{3046}",
7 "\x{3053}\x{305D}", "\n";
Wichtig ist es, dem Browser vorab im Header
mitzuteilen, welchem Codierungsverfahren die Seite folgt, in diesem
Fall setzt das Skript einfach den -charset-Parameter
der header-Methode des CGI-Moduls und schon weiß der Browser,
was Sache ist. Zu beachten ist, dass im String zwar Unicode-Konstanten
stehen, perl aber dennoch UTF-8 ausgibt, da es Strings intern in
UTF-8 speichert.
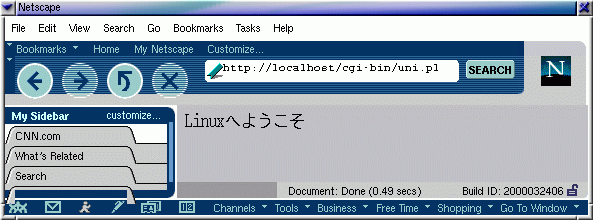 |
| Abb.3: "Willkommen bei Linux" auf Japanisch |
Nun zu etwas ganz anderem:
Wen die Schreibweise der neuen Perl-Version schon etwas verwundert hat
(5.6.0 statt 5.006_XX), dem sei gesagt:
Die Perl-Versionen folgen nun dem Linux-Versionssystem, nach dem
die ungeraden Releases Entwicklungsversionen sind und gerade
Versionsnummern stabile Distributionen kennzeichnen. Bugs in 5.6.0 werden
folglich in 5.6.1, 5.6.2 usw. korrigiert, während die nächste
Perl-Generation mit 5.7.0 beginnen wird. Sobald diese dann
Produktionsqualität annimmt, kommt mit 5.8.0 die nächste stabile
Generation daher.
Das schöne an dieser Neukonstruktion ist, dass diese Versionskonstanten eigentlich ganz normale Strings sind, deren Bytes die angegebenen Werte annehmen. Man schreibt
use v5.6.0;
um für ein Perl-Skript mindestens perl 5.6.0 vorauszusetzen.
Dann entspricht v5.6.0 dem String "\x{5}\x{6}\x{0}".
Die Spezialvariable $^V enthält die Version
der aktuellen perl-Version im gleichen Format und so kann man
mit String-Operatoren problemlos Vergleiche anstellen:
if ( $^V lt v5.6.1 ) {
print "Version kleiner als v5.6.1!\n";
}
Stehen 3 oder mehr Zahlenwerte aufgereiht, darf das ``v'' auch wegfallen. Die UTF-8-Kodierung entspricht, wie bereits weiter oben erläutert, im unteren (kleiner 128) ASCII-Bereich genau diesem. Entsprechend gibt
print 89.111.44.32.80.101.114.108.33, "\n";
den String
Yo, Perl!
aus, da ASCII 89 dem Buchstaben ``Y'' entspricht, ASCII 111 dem Zeichen ``o'', und so weiter.
Das CGI-Skript utf8.pl gibt auf japanisch insgesamt acht verschiedene
Zeichen aus, die jeweils in Dreierketten in UTF-8 angegeben wurden.
Abbildung 4 zeigt, wie der Satz im Browser aussieht. Angeblich bedeutet
er ``Ich bin Mike''.
Die ersten zwei Zeichen leiten
den Satz mit ``Ich'' und etwas grammatikalischem Firlefanz ein,
die nächsten drei sind
Katakana-Zeichen, die das Wort ``Mike'' lautzumalen versuchen, zwei
weitere Zeichen
runden den Satz mit ``bin'' grammatikalisch ab und das letzte Zeichen
markiert mit einem Punkt das Satzende.
Oha, das ist keine einfache Sprache nicht!
utf8.pl
1 #!/usr/bin/perl -w
2
3 use CGI qw(:all);
4 print header(-charset => 'utf-8');
5 # "Ich bin Mike" auf japanisch
6 print 229.131.149, 227.129.175, 227.131.158,
7 227.130.164, 227.130.175, 227.129.167,
8 227.129.153, 227.128.130;
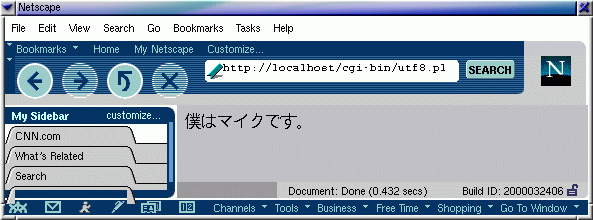 |
| Abb.4: "Ich bin Mike" auf Japanisch |
Auch für weiter hergeholte Anwendungen halten die Versionsstrings
her: Da die punktseparierten Einträge für Werte kleiner gleich 255 einfach nur
aneinander gereihte Bytes repräsentieren, lassen sich auch IPs so schreiben:
Der Versionsstring 127.0.0.1 packt 4 Bytes mit den Werten 127,
0 , 0 und 1 zusammen -- genau wie es zum Beispiel die Perl-Funktion
gethostbyaddr erwartet. Folgendes Skript sieht den Namen des Rechners
mit der IP 205.188.160.121 nach:
use Socket;
my ($host) = gethostbyaddr(205.188.160.121, AF_INET);
print "$host", "\n";
Der String "205.188.160.121" und der Versionsstring
205.188.160.121 unterscheiden sich grundsätzlich -- der hält
fünfzehn Bytes, der zweite nur vier.
Kommt nun zum Beispiel über die Kommandozeile ein String herein, biegt
ihn ein eval-Befehl in einen Versionsstring um, wie
folgenden Skript, das eine IP-Adresse als Parameter entgegennimmt und
den zugehörigen Rechnernamen per DNS-Lookup herausfindet:
my ($host) = gethostbyaddr(eval "$ARGV[0]", AF_INET);
Genug für heute! Sprecht fleißig japanisch!
perldoc perldelta, perldoc perlunicode,
perldoc utf8, perldoc bytes
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |