
Wer sagt, einem alten Hund könne man keine neuen Tricks beibringen? Heute bohren wir das gute alte POD-Format auf, um damit Zeitschriftenartikel wie diesen zu erstellen.
Wer Artikel mit einem ganz normalen ASCII-Editor wie
vi oder emacs erstellt, muss in den Text Markierungen einbauen, um
Absätze, Abbildungen, Listings, Codestücke, betonte Wörter
und vieles mehr zu kennzeichnen.
Üblicherweise halten hierfür Tags der Form
Ein
<EMPHASIS>wichtiges</EMPHASIS>
Wort wird hervorgehoben.
her, gängige Markierungssprachen sind SGML oder XML. Aus so markierten Texten generieren dann einfache Scripts jede beliebige Zielsprache wie HTML-Seiten, Vorlagen für FrameMaker, Quark Express, etc. -- alles geht, da die Markierungen eindeutige Meta-Informationen über den Text geben (z.B. Überschrift), die sich ohne Probleme in passende Formatierungskommandos (z.B. <H1>...</H1>) konvertieren lassen.
Das Problem mit Monstermarkierungen ist freilich, dass sie den Lesefluss gewaltig hemmen. Ein in der Entstehung begriffenes XML-Dokument kann der Autor nicht prüfen, ohne es bei jeder kleinen Korrektur ins Zielformat (z.B. HTML) umzuwandeln. Das ist lästig und behindert die Entwicklung.
Je mächtiger die Markierungssprache, desto unleserlicher das rohe Dokument. Beschränkt man sich aber auf die notwendigsten Befehle und nutzt außerdem gängige Plaintext-Konventionen (wie eine Leerzeile zwischen zwei Absätzen), lässt sich der erstellte Text a) mit allen notwendigen Metainformationen versehen und b) noch gut lesen.
Perls Manualseitensprache POD (Plain Old Documentation)
schafft diesen Spagat. Abbildung 1
zeigt einen typischen POD-Text, Abbildung 2 daneben die daraus
automatisch erzeugte HTML-Version. POD bietet allerdings nur simple
Strukturierungsanweisungen, für einen Zeitschriftenartikel fehlen
mindestens noch zwei elementare Dinge: Eine include-Anweisung,
die weitere Dateien, wie zum Beispiel Listings, hereinzieht und
ein figure-Kommando, das graphische Abbildungen einbindet.
| |
| Abbildung 1: In POD geschriebener Text -- lesbar trotz Metainformation |
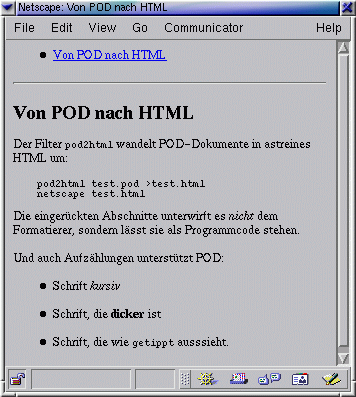 |
| Abbildung 2: Von POD automatisch nach HTML transformierter Text |
Aus diesem Grund nutze ich für die Snapshot-Artikel das
von mir frech so benannte
PND-(Plain New Documentation)-Format und ein kurzes Skript
pnd2pod, das das erweiterte Format ins gute alte POD wandelt.
Einmal bei POD angelangt, steht wieder das ganze Arsenal von
Filtern zur Verfügung, um HTML, LaTeX, DocBook
oder nroff-Formate zu generieren.
Bilder zieht in PND die =figure-Anweisung herein:
=figure fig/abb.jpg Das Bild!
Der erste ihr übergebene String gibt den Pfad zur Bilddatei an und aller nachfolgender Text auf der Zeile legt die Bildunterschrift fest.
Der =include-Anweisung hingegen gibt der Autor den Namen einer
wörtlich einzubindenden Datei mit. So lässt sich beispielsweise
jeden Monat elegant der gleiche Autorenkasten an den Artikel
anhängen:
=include ../data/footer.pod
Andererseits hält =include auch für Listings her.
PND geneniert sie aus ablauffähigen Skripts, die auf der
Festplatte liegen:
=include eg/pnd2pod listing
Diese Anweisung zieht die Datei pnd2pod im Verzeichnis eg
herein, nummeriert die Zeilen durch und klatscht
die Überschrift Listing pnd2pod darüber.
Das heute vorgestellte Skript pnd2pod liest eine PND-Datei,
ersetzt die PND-Tags durch POD-Tags und schreibt das Ergebnis in
eine *.pod-Datei.
Während die Transformation der =include-Anweisungen relativ
leicht zu bewerkstelligen ist, stellt sich die Frage, wie
eine Abbildung mittels =figure-Tag wohl in einem POD-Dokument
aussieht, da POD ja gar keine Bilder verarbeitet?
POD kümmert sich in der Tat nicht selbst um Abbildungen -- aber
es kann den nachfolgenden Formatierern Anweisungen geben, wie die
Abbildungen im Zielformat auszusehen haben. POD bietet hierzu
speziell markierte Bereiche, die POD selbst überspringt, die aber
ein pod2xxx-Formatierer lesen und beachten soll.
Steht in einem POD-Dokument beispielsweise
=for html
<IMG SRC=fig/linux.jpg>
<I> Ein Pinguin! </I>
=for text
Layoutabteilung: Hier bitte
das Bild fig/linux.jpg
einbinden. Danke!
dann greift sich der pod2html-Übersetzer den nach =for html
stehenden Absatz und bindet ihn wörtlich ins Zieldokument ein.
Der pod2text-Konvertierer hingegen ignoriert den html-Absatz
und schnappt sich statt dessen den nach =for text stehenden Text.
Genau so funktioniert pnd2pod. Es generiert einfach Anweisungen für
drei verschiedene Konvertierer: pod2html, pod2text und
pod2quark. Den letzteren gibt's noch nicht, den werden wir uns in der
nächsten Ausgabe des Perl-Snapshots selbst schreiben, um damit die vom
Linux-Magazin verwendeten Quark-Express-Macros zu generieren. Und
selbst wenn die Redaktion bald auf XML umstellt, reichen wir einfach
die Anweisungen für pod2xml in pnd2pod nach, schreiben
pod2xml und entwerfen die Artikel weiterhin in PND.
Und schon heute werden aus in PND geschriebenen Artikeln blitzschnell gut lesbare und bebilderte HTML-Dokumente:
pnd2pod artikel.pnd
pod2html artikel.pod >artikel.html
pnd2pod nimmt in alter Unix-Manier entweder Dateien auf der
Kommandozeile entgegen oder liest, falls keine vorliegen, von
der Standardeingabe. Zur Implementierung von pnd2pod,
das in Listing pnd2pod steht: Die Zeilen 6 und 7 definieren
die bislang einzigen Kommandos, die PND dem guten alten POD voraus hat:
figure und include. Im Hash %PND_COMMANDS ist wegen der
map-Anweisung dann jedem der beiden Strings der Wert 1 zugeordnet.
Um blitzschnell zu prüfen, ob PND ein bestimmtes Kommando unterstützt,
muss das Programm also nur im Hash %PND_COMMANDS nachsehen, ob
zu dem zugegebenen Kommandonamen ein Eintrag existiert.
Die in Zeile 9 und 10 definierten Variablen $IMAGE_COUNTER
und $LISTING_COUNTER zählen mit, wieviele Bilder und Listings
schon verarbeitet wurden und helfen so beim automatischen
Durchnummerieren.
Zeile 12 setzt den Namen der gerade verarbeiteten Datei, da pnd2pod
auch mehrere .pnd-Dateinamen auf der Kommandozeile entgegennimmt, diese
dann nacheinander bearbeitet, und das Ergebnis schließlich in die
entsprechenden .pod-Dateien ausgibt. Die nachfolgende while-Schleife
liest zeilenweise Dateien oder von der Standardeingabe ein und Perls
Spezialvariable $ARGV gibt immer akkurat an, welche Datei gerade
in der Mühle hängt. Zeile 17 bricht ab, falls es sich nicht um
eine mit der Endung .pnd versehene Datei handelt. Liest pnd2pod
von STDIN, steht $ARGV auf "-" und Zeile 18 berücksichtigt dies.
Zwischen zwei bearbeiteten Dateien schreibt Zeile 23 die bisher
gewonnenen Ergebnisdaten in die Zieldatei, die die ab Zeile
48 definierte Funktion flush_file einfach aus der gegenwärtigen
ermittelt, indem sie deren Endung .pnd durch .pod ersetzt.
Nach Abschluss der while-Schleife ruft Zeile 45 auch noch
einmal flush_file auf, um die in $data angesammelten Daten
entweder in die Standardausgabe oder die letzte Ausgabedatei loszuwerden.
Zeile 30 prüft, ob die gegenwärtige Zeile mit = anfängt, also ein
POD- oder PND-Kommando enthält. Der nachfolgende split()-Befehl
spaltet die Zeile an den Leerzeichen in eine Liste,
die das Kommando und die Parameterwerte als Elemente enthält.
So besteht pnd2pod derzeit auf Dateinamen, die keine Leerzeichen
enthalten -- das ließe sich mit etwas mehr Aufwand aber hinbiegen.
Zeile 34 prüft, ob es sich um eines der neuen PND-Kommandos handelt
und ruft, falls dem so ist, die gleichnamige Perl-Funktion mit den
festgelegten Parameterwerten auf.
Falls in $name der String "include" steht, ruft
$name->(@fields) einfach die ab Zeile 65 definierte
Funktion include() mit dem Parameter @fields auf.
Kämen in PND neue Kommandos hinzu, müsste
man nur %PND_COMMANDS in Zeile 6 erweitern und eine entsprechende
Handler-Funktion definieren -- die Hauptschleife bliebe bestehen.
001 #!/usr/bin/perl
002 ##################################################
003 # pnd2pod
004 ##################################################
005
006 my %PND_COMMANDS = map { $_ => 1 }
007 qw( figure include );
008
009 my $IMAGE_COUNTER = 1;
010 my $LISTING_COUNTER = 1;
011
012 my $current_file = $ARGV;
013 my $data = "";
014
015 while(<>) {
016
017 die "Not a pnd file: $ARGV" if
018 $ARGV !~ /\.pnd$/ and $ARGV ne "-";
019
020 if($ARGV ne "-" and $current_file ne $ARGV) {
021
022 # File changed, flush old file
023 flush_file($current_file, $data);
024
025 $current_file = $ARGV;
026 $data = "";
027 }
028
029 # Check if current line is a pnd line
030 if(/^=/) {
031 my @fields = split;
032 (my $name = shift @fields) =~ s/^=//;
033
034 if($PND_COMMANDS{$name}) {
035 # Call pnd handler function
036 $data .= $name->(@fields);
037 } else {
038 $data .= $_;
039 }
040 } else {
041 $data .= $_;
042 }
043 }
044
045 flush_file($current_file, $data);
046
047 ##################################################
048 sub flush_file {
049 ##################################################
050 my ($cur_file, $data) = @_;
051
052 if($cur_file ne "" and
053 $cur_file ne "-") {
054 (my $pod_file = $cur_file) =~ s/pnd$/pod/;
055 open OUT, ">$pod_file" or
056 die "Cannot open $pod_file";
057 print OUT $data;
058 close OUT;
059 }
060
061 print $data if $cur_file eq "-";
062 }
063
064 ##################################################
065 sub include {
066 ##################################################
067 my ($file, $options) = @_;
068
069 my $ln = 1;
070 my $text = "";
071 (my $name = $file) =~ s#.*/##;
072
073 open INFILE, "$file" or
074 die "Cannot open file <$file>";
075 my @infile = <INFILE>;
076 close(INFILE);
077
078 # No options -- just print it
079 unless($options) {
080 return join '', @infile;
081 }
082
083 my $len = @infile;
084 my $format = "%0" . length($len);
085
086 foreach my $line (@infile) {
087 $text .= sprintf "${format}d ",
088 $ln++ if $options eq "listing";
089 $text .= $line;
090 }
091
092 chop $text;
093 (my $indent_text = $text) =~ s/^/ /mg;
094 (my $html_text = $indent_text) =~ s/&/&/g;
095 $html_text =~ s/</</g;
096 $html_text =~ s/>/>/g;
097
098 my $ret = <<EOT;
099
100 =for html
101 <H2>Listing $LISTING_COUNTER: $name</H2>
102 <p>
103 <PRE>
104 $html_text
105 </PRE>
106 <P>
107
108 =for text
109 Listing $LISTING_COUNTER: $name
110 $indent_text
111
112 =for quark
113 \@KT: Listing $LISTING_COUNTER: $name
114 \@LI: [Hier bitte Listing $file.txt einfügen]
115
116 EOT
117
118 $LISTING_COUNTER++;
119 return $ret;
120 }
121
122 ##################################################
123 sub figure {
124 ##################################################
125 my ($file, @caption) = @_;
126 my $caption = join ' ', @caption;
127 my $ret = <<EOT;
128 =for html
129 <p>
130 <TABLE><TR><TD> <IMG SRC="$file"> <TR><TD>
131 <I>Abb.$IMAGE_COUNTER: $caption</I>
132 </TABLE>
133 <p>
134
135 =for text
136 Abbildung $IMAGE_COUNTER: $caption ("$file")
137
138 =for quark
139 \@Bi:$file
140 \@B:Abb. $IMAGE_COUNTER: $caption
141
142 EOT
143
144 $IMAGE_COUNTER++;
145 return $ret;
146 }
Ganz wie das =include-Kommando nimmt auch die include()-Funktion
in pnd2pod bis zu zwei Parameter entgegen: Den Namen der einzubindenden
Datei und das optionale Schlüsselwort "listing", das include()
dazu veranlasst, die Datei nicht nur einfach einzubinden, sondern
nach einer Überschrift Listing n: NAME die durchnummerierten
Zeilen der Datei ohne zusätzliche Formatierungsschritte anzuzeigen.
Wie alle Handlerfunktionen schreibt include() nicht selbst auf
die Standardausgabe, sondern gibt nur einen String als Ergebnis
zurück.
Zwischen den Zeilen 73 und 76 liest include() die einzubindende Datei
auf einen Rutsch in den Array @infile ein, der dann pro Element
eine Dateizeile enthält. Fehlt beim Aufruf von include() das
Schlüsselwort "listing" in $option, gibt Zeile 80 einfach
den Dateiinhalt als mit join zusammengeschweißten String zurück.
Um Listings durchzunummerieren braucht man heutzutage auch schon
Abitur, denn
falls die Datei 9 Zeilen lang ist, laufen die Zeilennummern von 1 bis 9,
falls sie bis zu 99 Zeilen lang ist, von 01 bis 99, über 100 Zeilen
lange Dateien weisen Zeilennummern von 001 bis 999 auf. include()
muss also zunächst feststellen, wieviele Zeilen die einzubindende
Datei denn enthält. Diese Zahl legt Zeile 83 in $len ab, indem
sie einfach @infile in skalaren Kontext stellt und so seine Länge erfährt.
Zeile 84 findet mit length() heraus,
aus wievielen Ziffern $len besteht und
generiert %01, %02, %03 etc. als Formatstring für
die sprintf-Anweisung in Zeile 87, die dann %01d, %02d,
%03d etc. daraus macht und linksbündig mit Nullen aufgefüllte
Zeilennummern gleicher Länge generiert.
Die Zeilen 92 bis 96 rücken dann den Text noch etwas ein und
maskieren die Zeichen &, < und >, damit's später im
HTML keine Probleme gibt.
Das ab Zeile 98 definierte Here-Dokument schreibt drei Sektionen ins POD: Eine für HTML, eine für Klartext und eine für's zukünftig unterstützte Quark-Format. Für die beiden letztgenannten Konvertierer wird der Listingtext nicht direkt eingebunden, sondern nur mit einem kurzen Vermerk auf die entsprechende Skriptdatei verwiesen. Die Setzer beim Verlag nehmen sich ihrer dann manuell an. Zeile 119 gibt das Ergebnis Handler-typisch als String ans Hauptprogramm zurück, das es dann bei Gelegenheit in die Ergebnisdatei schreibt.
Stößt pnd2pod auf eine =figure-Anweisung, ruft Zeile
36 im Hauptprogramm einfach die ab Zeile 123 definierte Funktion
figure() auf. Diese nimmt den Bilddateinamen entgegen und die
Bildunterschrift, die wegen des split-Befehls in Zeile 32
in einzelne Worte aufgespalten wurde. Zeile 126 setzt diese wieder
im String $caption zusammen. Für HTML generiert figure()
einen <IMG>-Tag, der direkt auf die Bilddatei verweist
und den Browser dazu veranlasst, sie im Dokument darzustellen.
Für die Text- und Quarkkonvertierer beschreitet figure() den
Weg, den include() auch schon ging, indem es lediglich Anmerkungen
für die Satzabteilung generiert, die dann die Bilder manuell zusammensucht.
Nach den Autorenrichtlinien [2] bezeichnet in dem im Linux-Magazin
üblichen Quarkformat die Sequenz
@Bi: am Zeilenanfang eine nachfolgende Bilddatei, ein nachfolgendes
@B: bestimmt die Bildunterschrift:
@Bi:eg/linux.jpg
@B:Abb. 7: Powered by Linux
Mit diesen Quark-Makros beschäftigen wir uns das nächste Mal im Detail
-- wenn wir nämlich unseren Quark-Konvertierer pod2quark
zusammenstricken, der aus dem heute hergestellten verquarkten POD
endlich reines Quark generiert. Esst viele gesunde
Milchprodukte -- bis zum nächsten Mal!
perldoc perlpod erläutert das POD-Format
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |