Mit der in [1] ausführlich vorgestellten DBI-Schnittstelle spricht Perl mit der frei verfügbaren Datenbank MySQL, um die Betriebszeiten von Servern festzuhalten und SQL-Queries zur statistischen Auswertung zu fahren.
Neulich stand ich vor einer Farm hin und wieder abstürzender/wiederstartender Applikationsserver. Ich wollte herausfinden, wie oft am Tag dies passierte, zu welchen Tageszeiten und auf welchen Servern. Jeder Server bot einen URL an, über den man über's Web die ``Uptime'' seiner Applikationsserver abfragen konnte.
Da dachte ich mir: Warum schreibe ich mir kein Perlskript, das die Server einmal pro Minute abklappert, sich die ``Uptimes'' merkt, und Alarm schlägt, falls eine ``Uptime'' kleiner als der zuletzt gemerkte Wert ist, der Server also offensichtlich wieder durchstartete?
Und, um meine schon etwas rostig gewordenen SQL-Kenntnisse aufzupolieren: Warum installiere ich mir dazu keine Datenbank und lege die Ergebnisse nach Datum geordnet dort ab, damit ich später in den gesammelten Daten mittels schlauer SQL-Abfragen nach Herzenslust herumwühlen kann?
Mit Perl lässt sich derlei ja flugs aus dem Hut zaubern. Wir brauchen dazu nur von [2] die MySQL-Binär-Distribution abzuholen und zwei Perl-Module zu installieren (siehe Abschnitt Installation).
Datenrecords
in der relationalen Welt liegen untereinander
in Tabellen, deren Spalten die verschiedenen Datenfelder repräsentieren
und auch das Ergebnis von SQL-Abfragen liegt wieder in Tabellenform vor.
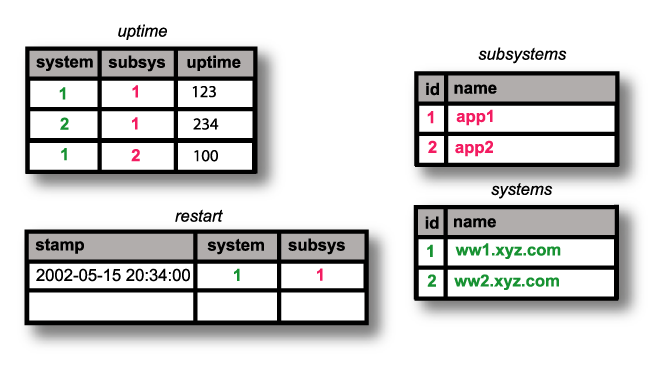
Abbildung [1] zeigt
die vier Tabellen, die das Perlskript create_tables.pl
für das vorliegende Problem anlegte. Zunächst ein kleiner
SQL-Wiederholungskurs: Um abzuspeichern,
welches System (festgelegt z. B. durch eine Hostadresse)
und welches Subsystem
(z. B. Name des Applikationsservers) welche ``Uptime'' lieferten, könnte
man wie folgt verfahren:
System Sub Uptime
ww1.xyz.com app1 456
ww2.xyz.com app1 234
ww1.xyz.com app2 100
ww1.xyz.com app1 123
Allerdings ist das redundant, da lange Host- und Subsystemnamen mehrfach ausgeschrieben im Datenbestand hängen. In der relationalen Welt geht man derartigen potentiellen Wartungszeitbomben aus dem Weg, in dem man in der Haupttabelle nur kurze numerische IDs angibt, die man in zusätzlichen Tabellen dann den wirklichen Werten zuweist.
Abbildung [1] zeigt, dass die Tabelle systems (rechts unten) den Hostnamen numerische IDs zuordnet, subsystems (rechts oben) Applikationsserver durchnumeriert und schließlich die Tabelle uptime die Uptimes verschiedener Systeme speichert, indem es den ermittelten Sekundenwert neben den IDs von Hostnamen und Subsystem ablegt.
| |
| Abbildung 1: Tabellen |
Mittels geschickter SQL-Befehle lässt sich, wie wir später sehen werden, dann die ursprüngliche Repräsentation mit ausgeschriebenen Namen leicht wieder herstellen.
Das in Abbildung [1] dargestellte Datenbankschema enthält noch eine weitere Tabelle namens Restarts, die jeweils unter einem Datums- und Zeitstempel (stamp) festhält, dass ein bestimmer Applikationsserver durchgestartet ist.
Woher stammen die Daten? Nehmen wir an, dass ein Skript in regelmäßigen
Abständen ermittelt, wie lange (in Sekunden)
die verschiedenen Applikationsserver
auf den verschiedenen Rechnern schon laufen.
Das weiter unten vorgestellte Skript add, das einen Rechnernamen,
den Namen des
Applikationsservers und die ``Uptime'' in Sekunden entgegennimmt, prüft nun, ob
das System schon in der Tabelle uptime der Datenbank
gespeichert ist. Falls nicht, legt es
einen neuen Eintrag an. Dann prüft es, ob der neu
ermittelte Wert eine größere Sekundenzahl aufweist als der in
der Datenbank gespeicherte Wert.
Falls ja,
schnurrt der Server noch brav vor sich hin, und add wird lediglich
den in der Tabelle
gepeicherten Sekundenwert mit dem neuen Uptime-Wert auffrischen.
Ist der neue Wert hingegen kleiner als der gespeicherte,
hat's den Server wohl zwischenzeitlich zerlegt und er ist
wieder durchgestartet. Nachdem add
den Wert in uptime aufgefrischt hat, legt es gleich noch einen
Eintrag in der Tabelle restarts an, die unter dem aktuellen
Datums- und Zeitstempel die IDs der durchgestarteten Komponente ablegt.
Später können wir dann seelenruhig SQL-Skripts über restarts
laufen lassen und Statistiken darüber erstellen, wie oft ein
bestimmter Server in der Farm pro Monat verrückt spielt.
Ein Beispiel mit dem unten vorgestellten Skript add: Die Befehlsfolge
add ww1.xyz.com app1 456
add ww2.xyz.com app1 234
add ww1.xyz.com app2 100
add ww1.xyz.com app1 123
meldet der Datenbank vier Serverzustände. Die ersten drei beziehen sich auf drei unterschiedliche Systeme bzw. Subsysteme, die 456, 234 und 100 Sekunden Uptime bekanntgaben. Der vierte Eintrag stammt vom selben System wie der in Zeile 1 und gibt bekannt, dass die neue Uptime 123 Sekunden beträgt.
Ausgehend von einer Datenbank mit leeren Tabellen, stellt add.pl
fest, dass es für ww1.xyz.com noch keinen Eintrag in der
Tabelle systems gibt und legt ihn wie in Abbildung 1 illustiert
unter der Indexnummer 1 an. Ähnliches gilt für die Tabelle
subsystems, in die add.pl einen Eintrag für app1 unter
der ID 1 pumpt.
In der Tabelle uptime ist noch nichts über ww1.xyz.com/app1
bekannt, also legt app.pl dort einen Eintrag mit 456 Sekunden Uptime
unter den IDs 1 und 1 ab (erste Tabellenzeile in Abbildung 1).
Ähnliches gilt für das zweite und dritte add.pl-Kommando oben.
Danach hängen, wie Abbildung 1 zeigt, drei Einträge in uptime,
zwei in systems und zwei in subsystems.
Der vierte add.pl-Befehl meldet eine kleinere Uptime als der erste
und deshalb wird die dritte Spalte der ersten Zeile der Tabelle uptime
von 456 auf 123 korrigiert.
add.pl stellt den Restart des Systems fest und legt ihn unter dem
aktuellen Datum in der Tabelle restarts ab. Abbildung 1 zeigt den Endstand.
In der Tabelle uptime stehen also stets die zuletzt erhaltenen Uptime-Werte
aller Systeme und Subsysteme, während restarts ein chronologisches
Logbuch führt, das jeden Durchstart mit Uhrzeit und Datum festhält.
Die Tabelle uptime bleibt also irgendwann konstant (sobald keine
``neuen'' Systeme mehr dazukommen), während restarts kontintuierlich
wächst.
Abbildung 2 zeigt die Ausgabe der Tabellenendstände mittels
des Clientprogramms mysql, das der MySQL-Distribution beiliegt.
Mit ihm kann man schön die Struktur der im MySQL-Server
gespeicherten Datenbanken analysieren und nach Belieben SQL-Befehle auf
sie abfeuern.
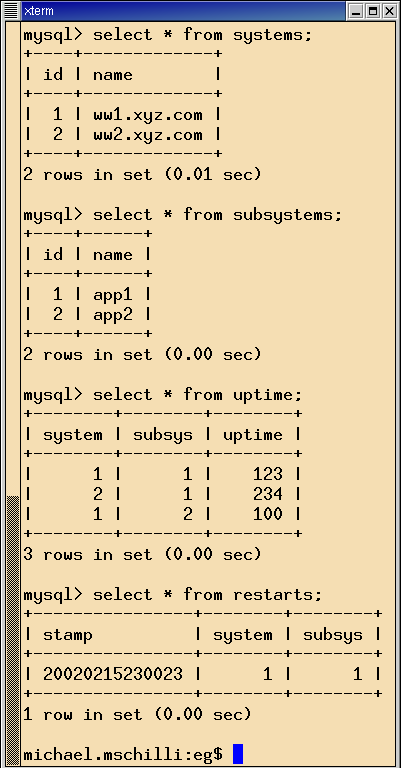 |
|
Abbildung 2: Tabellenanzeige mit dem C |
Zuerst brauchen wir die Datenbank MySQL, die auf [2] frei erhältlich ist.
mysql-3.23.47 war die zur Drucklegung aktuelle Version. Ist der
Tarball mit
# cd /usr/local
# tar zxfv mysql-3.23.47-pc-linux-gnu-i686.tar.gz
im Installationsverzeichnis entpackt (im Beispiel /usr/local),
legt man mit
# ln -s mysql-3.23.47-pc-linux-gnu-i686.tar.gz mysql
einen symbolischen Link im selben Verzeichnis an.
Nun brauchen wir noch einen zusätzlichen
Benutzer mysql der Gruppe mysql im Unix-System, legen diese
also unter root mit
# /usr/sbin/groupadd mysql
# /usr/sbin/useradd -g mysql mysql
an und initialisieren mit
# cd /usr/local/mysql
# scripts/mysql_install_db
die Datenbank. Anschließend legen wir den Eigentümer mit
# cd ..
# chown -R root mysql
# chown -R mysql mysql/data
als mysql für die Datenbankdaten und root für den Rest fest.
Anschließend kann der Dämon mit
# cd mysql
# bin/safe_mysqld --user=mysql &
starten. Wer ihn automatisch beim Booten der Linux-Kiste oben
haben will, nimmt die mitgelieferte Datei support-files/mysql.server,
passt die in ihr enthaltenen Pfade (/usr/local) an die lokalen Gegebenheiten
an und stellt sie, da sie bereits die Kommandozeilenparameter start
und stop versteht, in das Verzeichnis für den Linuxstart -- unter
Redhat beispielsweise mit
# cp support-files/mysql.server /etc/rc.d/init.d
# cd /etc/rc.d/rc3.d
# ln -s ../init.d/mysql.server S86mysql
# ln -s ../init.d/mysql.server K06mysql
Die Datenbank ist nun zwar ungeschützt und der Datenbankbenutzer
root (übrigens
nicht verwandt mit dem gleichnamigen Unix-Benutzer) braucht
kein Passwort anzugeben, aber für den privaten Gebrach sollte das okay sein.
An Perl-Modulen brauchen wir zwei. Das allgemeine Datenbankinterface
DBI und den speziellen DBD::mysql-Treiber. Wenn wir zum PATH
der Shell auch noch den Pfad zum bin-Verzeichnis der MySQL-Installation
hinzufügen und perl folglich das Programm mysql_config findet, geht
die Installation wie geschmiert vom CPAN:
$ export PATH=$PATH:/usr/local/mysql/bin
$ perl -MCPAN -eshell
cpan> install DBI
cpan> install DBD::mysql
Anschließend legen wir in MySQL eine neue Datenbank mit vier Tabellen
gemäß Abbildung 1 an. Das geht entweder mit dem mitgelieferten
mysql-Client oder, da wir uns ja gerade in einer Perl-Kolumne befinden,
mit Perl. Listing create_tables.pl zieht hierzu in Zeile 9 das
generische Datenbankmodul DBI herein, das die Schnittstelle zu
beliebigen Datenbanken (Oracle, Sybase, Flatfile [3] etc.)
schön abstrahiert. Da wir für MySQL keine Benutzerberechtigungen
oder auch nur ein Root-Passwort anlegten, definieren die Zeilen 11 und 12
den MySQL-Benutzer, unter dem das Skript auf die Datenbank zugreift,
als ``root'' fest und die $PASSWORD-Variable bleibt leer.
Zeile 15 installiert den richtigen Treiber für MySQL und
liefert eine Referenz auf ein entsprechendes Objekt zurückt.
Zeile 16 legt damit im MySQL-Server auf dem localhost
eine neue logische Datenbank mit dem Namen
serverdaten an. Zu dieser nimmt Zeile 21 in typischer DBI-Manier
Kontakt auf. Spezifiziert werden das Datenbank-Interface (DBI), der
Treiber mysql, die Datenbank (serverdaten), Benutzername und
Passwort, sowie eine Referenz auf einen Hash mit Optionen. Wir
setzen PrintError auf einen falschen Wert, da DBI sonst standardmäßig
wüste Warnungen auf STDERR ausgibt, falls etwas schiefgeht. Eine
weitere, oft genutzte Option ist RaiseError, die DBI-Funktionen sofort
eine die-Exception werfen lässt, falls etwas schiefgeht. Das soll
im vorliegenden Skript aber nicht geschehen, vielmehr sollen die Funktionen
schweigen und ganz normal Fehlerwerte zurückliefern,
falls etwas nicht klappt.
Die connect-Methode liefert ein Datenbank-Handle (eigentlich
eine Referenz auf ein DBI-Objekt), über dessen Methoden die
weiteren Zugriffe auf die Datenbank erfolgen.
Die erste anzulegende Tabelle ist (nach Abbildung [1]) systems, die
den System-Namen Integer-Werte zuordnet. Falls schon eine Tabelle
system in der Datenbank serverdaten existiert, lässt
Zeile 26 sie mittels des SQL-Befehls DROP verschwinden. Schließlich
soll create_tables.pl auch dann funktionieren, wenn die ganze Datenbank
kaputt ist und wir nur schnellstens wieder bei Null anfangen wollen.
Das zahlt sich insbesondere während der Skriptentwicklung aus, wenn
noch nicht alles 100% funktioniert.
Existiert die Tabelle noch gar nicht, schlägt DROP fehl, was Zeile
26 aber geflissentlich ignoriert.
Die Zeilen 27 bis 33 setzen anschließend einen CREATE-SQL-Befehl
an die Datenbank ab, der die Tabelle mit zwei Spalten erzeugt.
In der ersten steht eine Integerzahl (Typ MEDIUMINT),
die von MySQL automatisch mit jedem
neuen Datensatz um eins hochgezählt wird (AUTOINCREMENT).
Derlei Syntax ist kein Standard-SQL, sondern abhängig von der
jeweils verwendeten Datenbank. Neben der ausgezeichneten
Online-Dokumentation auf [2] kann ich [4] empfehlen, um sich
in die Besonderheiten von MySQL einzuarbeiten. Dort erfährt man
dann, dass ein MEDIUMINT bis zu 16 Millionen und ein paar
Zerquetschten wachsen darf -- das dürfte für's Erste genügen.
Auch [5] eignet sich, wenn man nur Dinge nachschlagen muss, die man
schon mal wusste.
Die Perl-Syntax $dbh->do(<<EOT) in Zeile 27
leitet ein Here-Dokument ein, das die nachfolgenden Zeilen als einzigen
String an die Methode do() übergibt, bis sich eine Zeile findet,
die nur den String "EOT" am Zeilenanfang enthält. In den Zeilen 28-32 steht
also reines SQL, das das Skript an die Datenbank schickt.
Zur SQL-Tabellendefinition: Der Ausdruck
name VARCHAR(255) definiert ein Datenfeld als String, der bis zu
255 Zeichen lang sein kann. PRIMARY KEY (id) legt fest, dass
die erste Spalte der Tabelle der Primärschlüssel ist,
nach dem das Datenbankgetriebe die Tabelle indiziert und demnach
blitzschnell den zugehörigen Datensatz findet, falls man die
ID weiss. Das ist schließlich unser Ziel: Die später definierten
Tabellen uptime und restarts werden nur IDs speichern, die
wiederum in sytems und subsystems auf die entsprechenden Namen
verweisen. Geht's an die Anzeige, muss die Umwandlung zack-zack gehen,
deswegen die Indizierung über den Primary-Key.
Das UNIQUE-Attribut legt fest, dass die in name
definierten Namen eindeutig
sein müssen, zweimal dasselbe System einzutragen, wäre sinnlos, hierzu
aber später.
uptime schließlich wird ab Zeile 47 definiert, mit zwei Spalten
system und subsystem, in denen, das ist kein Zufall, die IDs für's
System und Subsystem stehen, die die Tabellen systems und
subsystems in Namen auflösen können. Die NOT NULL-Direktive weist
MySQL an, einen Fehler zu melden, falls jemand versucht, einen Eintrag
zu generieren, der diese Spaltenwerte nicht setzt.
Das dritte Feld uptime ist ein INTEGER und gibt die vom
System/Subsystem gemeldete Uptime in Sekunden an. Wird sie nicht
spezifiziert, setzt MySQL sie wegen der Direktive DEFAULT 0 auf 0.
Ab Zeile 57 schließlich entsteht die Tabelle restarts, die
angibt, zu welchem Zeitpunkt ein System/Subsystem durchstartete.
Der Datentyp TIMESTAMP gibt in MySQL das aktuelle Datum mit
Uhrzeit an und wird von MySQL automatisch auf die aktuelle Uhrzeit
gesetzt, falls es sich um die erste Spalte der Tabelle handelt, die
einen Wert vom Typ TIMESTAMP erwartet. Ereignet sich ein Restart,
müssen wir später MySQL nur anweisen, eine neue Tabellenzeile
mit System- und Subsystem-ID anzulegen, und es wird automatisch das
aktuelle Datum davorsetzen -- praktisch.
create_tables.pl legt, einmal von der Kommandozeile aufgerufen,
in der laufenden Datenbank mit den leeren Tabellen
den Grundstein für die weiteren Aktionen.
01 #!/usr/bin/perl
02 ###########################################
03 # create_tables.pl -- DB/Tabellen anlegen
04 # Mike Schilli, 2002 (m@perlmeister.com)
05 ###########################################
06 use warnings;
07 use strict;
08
09 use DBI;
10
11 my $USER = "root";
12 my $PASSWORD = "";
13
14 # Set up Database
15 my $drh = DBI->install_driver("mysql");
16 my $rc = $drh->func("createdb",
17 "serverdaten", "localhost",
18 $USER, $PASSWORD, 'admin');
19 warn "Create failed ($rc)" unless $rc;
20
21 my $dbh = DBI->connect("DBI:mysql:" .
22 "database=serverdaten;host=localhost",
23 $USER, $PASSWORD, {PrintError => 0});
24
25 # === Table "SYSTEMS" ===
26 $dbh->do("DROP TABLE systems");
27 $dbh->do(<<EOT) or die "CREATE failed";
28 CREATE TABLE systems (
29 id MEDIUMINT AUTO_INCREMENT,
30 name VARCHAR(255) UNIQUE,
31 PRIMARY KEY (id)
32 )
33 EOT
34 # === Table "SUBSYSTEMS" ===
35 $dbh->do("DROP TABLE subsystems");
36 $dbh->do(<<EOT) or die "CREATE failed";
37 CREATE TABLE subsystems (
38 id MEDIUMINT AUTO_INCREMENT,
39 name VARCHAR(255) UNIQUE,
40 PRIMARY KEY (id)
41 )
42 EOT
43
44 # === Table "UPTIME" ===
45 $dbh->do("DROP TABLE uptime");
46 $dbh->do(<<EOT) or die "CREATE failed";
47 CREATE TABLE uptime (
48 system MEDIUMINT NOT NULL,
49 subsys MEDIUMINT NOT NULL,
50 uptime INTEGER DEFAULT 0
51 )
52 EOT
53
54 # === Table "RESTARTS" ===
55 $dbh->do("DROP TABLE restarts");
56 $dbh->do(<<EOT) or die "CREATE failed";
57 CREATE TABLE restarts (
58 stamp TIMESTAMP,
59 system MEDIUMINT NOT NULL,
60 subsys MEDIUMINT NOT NULL
61 )
62 EOT
63
64 $dbh->disconnect();
Listing add stellt ein Kommandozeileninterface für die
Funktion update_add() bereit, die das Ergebnis einer Serverprüfung
an die Datenbank übermittelt. In Zeile 14 wirft es eine Exception,
falls es nicht mit drei Parametern für Systemnamen, Subsystemnamen
und einer Uptime in Sekunden aufgerufen wurde. Die Zeilen 17-19 knüpfen
die Verbindung zur MySQL-Datenbank und stellen mit RaiseError
ein, dass die DBI-Schnittstelle bei Fehlern sofort Exceptions wirft.
Die in den Zeilen 29 und 31 aufgerufenen Funktion sysname_to_id()
liefert zu einem System- oder Subsystemnamen eine numerische ID, indem
sie (ab Zeile 64) zunächst versucht, aus der entsprechenden Tabelle
(systems oder subsystems) eine bereits bestehende ID zu holen, oder,
falls zum vorgegebenen Namen noch keine existiert, mit INSERT
eine neue anzulegen.
Anschließend ruft
Zeile 35 die Methode selectrow_array() des DBI-Moduls auf,
das ein ihr übergebenen SQL-Kommando an die Datenbank weitergibt,
und solange Listen mit den Ergebnisspalten des Queries zurückgibt,
bis das Ende der Ergebnistabelle erreicht ist. Der Query ab Zeile
37 fragt nur nach einer Spalte (der Uptime eines Systems/Subsystems
in der Tabelle uptime), deswegen besteht die Ergebnisliste ebenfalls
jeweils nur aus einem Wert ($db_uptime). Falls ein Uptime-Wert
in der Datenbank steht und dieser größer als der der Funktion
übergebene Wert $uptime ist, ruft Zeile 43 die Funktion restart_add()
auf, die einen Eintrag in der Tabelle restarts vornimmt, da das System
offensichtlich abgekracht und wieder angelaufen ist.
In jedem Fall muss der Wert für die Spalte uptime
in der Datenbanktabelle uptime für das entsprechende System
mittels des SQL-UPDATE-Kommandos ab Zeile 47 aufgefrischt werden.
Die WHERE-Klausel wählt hierzu mit einer Bedingung für
die Spalten system und subsys die richtige Zeile aus und
setzt uptime. Die in Zeile 52 aufgerufene do()-Methode lässt
die Datenbank es tatsächlich tun.
Wurde noch keine Uptime für das aktuell behandelte System in
der Datenbanktabelle uptime gefunden, kommt der SQL-INSERT-Befehl
ab Zeile 56 zum Zuge, der einfach eine neue Zeile mit dem aktuellen
Wert für das System anlegt.
sysname_to_id() ab Zeile 64 nimmt das Datenbank-Handle $dbh,
den Tabellennamen ("systems" oder "subsystems") und den
Namen des (Sub)-Systems entgegen, dessen ID gefunden oder neu
angelegt werden soll. Zeile 68 nutzt die Methode quote() des
Datenbank-Handles, um den String $name nach SQL-Vorschriften
zu maskieren und in einfache Anführungszeichen zu setzen.
Die selectrow_array()-Methode ab Zeile 70 führt den SELECT-Befehl
auf der Datenbank aus, der eine einspaltige und einzeilige Ergebnistabelle
zum Ergebnis hat, falls die ID in der Datenbank existiert: Den
Wert für die dem Namen zugeordnete numerische ID. Falls der
Name nicht gefunden wurde, stellt dies Zeile 75 anhand des undefinierten
Wertes für $id fest und setzt einen INSERT-Befehl ab, der
einen neuen Eintrag mit automatisch generierter Seriennummer
(wegen der AUTO_INCREMENT-Eigenschaft der ID-Spalte in der
Tabellendefinition) einfügt,
die der SELECT-Befehl ab Zeile 80 wieder aus der Datenbank extrahiert.
In jedem Fall gibt Zeile 85 die entweder alte oder frisch generierte
ID zurück.
restart_add() ab Zeile 89 nimmt ein Datenbank-Handle, eine
System-ID und eine Subsystem-ID entgegen und fügt mit
einem SQL-INSERT-Kommando eine neue Zeile in die Tabelle
restart ein, um ein Restart-Ereignis unter dem aktuellen
Datum und der aktuellen Uhrzeit festzuhalten. Obwohl INSERT
außer den beiden IDs nichts angibt, fügt MySQL automatisch
einen Zeitstempel in die erste Spalte des Eintrags ein, da
in der Tabellendefinition (Listing create_tables.pl, Zeile
58) dort ein Typ TIMESTAMP steht, deren ersten
MySQL immer durch den aktuellen Zeitstempel ersetzt, falls explizit nichts
anderes angegeben wurde.
Noch ein Wort zu sysname_to_id:
Fummeln mehrere Prozesse gleichzeitig an der Datenbank herum,
könnte es sein, dass zwei feststellen, dass ein neues System
nach system muss, und sich dann beide anschicken, einen neuen
Eintrag zu generieren. Die UNIQUE-Definition der name-Spalte
(Zeilen 30/39 in create_tables.pl)
erlaubt jedoch keine doppelten Einträge und die Datenbank würde
einen Fehler melden. Das IGNORE-Schlüsselwort im INSERT-Query
(Zeile 77 in add)
unterdrückt die Meldung, die in diesem Fall auch sinnlos wäre.
So drücken wir uns elegant darum, Tabellen zu sperren, um
doofe Race-Conditions zu vermeiden.
01 #!/usr/bin/perl
02 ###########################################
03 # add -- Handle uptime check
04 # Mike Schilli, 2002 (m@perlmeister.com)
05 ###########################################
06 use warnings;
07 use strict;
08
09 use DBI;
10
11 my $USER = "root";
12 my $PASSWORD = "";
13
14 die "usage: $0 system subsystem uptime" if
15 @ARGV != 3;
16
17 my $dbh = DBI->connect("DBI:mysql:" .
18 "database=serverdaten;host=localhost",
19 $USER, $PASSWORD, {RaiseError => 1});
20
21 uptime_add( $dbh, @ARGV );
22
23 ###########################################
24 sub uptime_add {
25 ###########################################
26 my($dbh, $system, $subsys,
27 $uptime) = @_;
28
29 my($sys_id) = sysname_to_id($dbh,
30 "systems", $system);
31 my($sub_id) = sysname_to_id($dbh,
32 "subsystems", $subsys);
33
34 # Last uptime for this system
35 my($db_uptime) =
36 $dbh->selectrow_array(<<EOT);
37 SELECT uptime FROM uptime
38 WHERE system = $sys_id AND
39 subsys = $sub_id
40 EOT
41
42 if(defined $db_uptime) {
43 restart_add($dbh, $sys_id, $sub_id)
44 if $db_uptime > $uptime;
45
46 my $sql = <<EOT;
47 UPDATE uptime
48 SET uptime = $uptime
49 WHERE system = $sys_id AND
50 subsys = $sub_id
51 EOT
52 $dbh->do($sql);
53 } else {
54 # No uptime for this system yet?
55 $dbh->do(<<EOT);
56 INSERT INTO uptime (system,
57 subsys, uptime)
58 VALUES ($sys_id, $sub_id, $uptime)
59 EOT
60 }
61 }
62
63 ###########################################
64 sub sysname_to_id {
65 ###########################################
66 my($dbh, $table, $name) = @_;
67
68 my $qname = $dbh->quote($name);
69
70 my($id) = $dbh->selectrow_array(<<EOT);
71 SELECT id FROM $table
72 WHERE name = $qname
73 EOT
74
75 unless(defined $id) {
76 $dbh->do(<<EOT);
77 INSERT IGNORE INTO $table (name)
78 VALUES ($qname)
79 EOT
80 $id = $dbh->selectrow_array(<<EOT);
81 SELECT id FROM $table
82 WHERE name = $qname
83 EOT
84 }
85 return($id);
86 }
87
88 ###########################################
89 sub restart_add {
90 ###########################################
91 my($dbh, $sys_id, $sub_id) = @_;
92
93 $dbh->do(<<EOT);
94 INSERT INTO restarts (system,
95 subsys)
96 VALUES ($sys_id, $sub_id)
97 EOT
98 }
Mit den so gespeicherten Daten lassen sich allerhand interessante Statistiken
erstellen und schön formatiert mit CGI-Skripts im Browser anzeigen.
Listing show.pl zeigt als Beispielanwendung ein Skript, das einen
SQL-Befehl an die Datenbank absetzt und daraufhin alle bekannten Systeme
und die Zahl ihrer Restarts während der letzten 24 Stunden anzeigt.
Der SQL-Befehl von Zeile 24 bis 31 vereint die Tabellen restarts,
systems und subsystems, um die Systeme nicht nur der ID, sondern
dem Namen nach anzuzeigen. SQL hat die angenehme Eigenschaft, dass man
Tabellen miteinander verknüpfen und in unserem Fall IDs wieder
in Systemnamen umwandeln kann. So ergibt
SELECT systems.name, subsystems.name
FROM systems, subsystems
im oben durchgerechneten Beispiel die Tabelle mit allen System/Subsystemkombinationen:
+-------------+------+
| name | name |
+-------------+------+
| ww1.xyz.com | app1 |
| ww2.xyz.com | app1 |
| ww1.xyz.com | app2 |
| ww2.xyz.com | app2 |
+-------------+------+
Dieser im Datenbankchinesisch sogenannte Join spiegelt allerdings
nicht die Wirklichkeit wider, da es dort (siehe Beispiel oben)
keine Kombination von ww2.xyz.com und app2 gibt. Eine
WHERE-Klausel, die systems.id = restarts.system und
subsystems.id = restarts.subsys zur Bedingung stellt, reduziert
die aufmultiplizierte Tabelle auf ``wahre'' Kombinationen.
Ein count(*)-Eintrag im SELECT zählt normalerweise einfach
alle Zeilen der Ergebnistabelle. Hängt dem SELECT allerdings noch
eine GROUP BY-Direktive an, fasst der Datenbankmotor
Einträge mit gleicher Gruppeneigenschaft (in show.pl eine
Kombination aus System- und Subsystem-ID) zusammen und lässt
count(*) die Anzahl der Einträge der jeweiligen Gruppen bestimmen.
In show.pl zählt count(*) also, wieviele Einträge für ein
bestimmtes System vorliegen.
Um nicht die ganze Datenbank durchzuorgeln, sondern uns auf die
Daten der letzten 24 Stunden zu beschränken, bestimmt die WHERE-Klausel
mit
DATE_ADD(stamp, INTERVAL 1 DAY) > CURRENT_TIMESTAMP
dass das Datum, das man erhält, wenn man zum Zeitstempel der jeweiligen Zeile einen Tag addiert größer sein muss als das aktuelle Datum mit Uhrzeit -- SQL-Deutsch für ``gib mir nur Einträge, deren Zeitstempel nicht älter als ein Tag ist''.
Das CGI-Skript nutzt das CGI-Modul und dessen hier schon öfter
vorgestellte Funktionen zur Ausgabe von HTML-Tabellen. Nach ein
paar weiteren add-Aufrufen zeigt es die Kracher wie in
Abbildung 3 gezeigt an. Erfindet eure eigenen Statistiken!
01 #!/usr/bin/perl
02 ###########################################
03 # show -- Show summary of last 24 hours
04 # of "RESTARTS" table.
05 # Mike Schilli, 2002 (m@perlmeister.com)
06 ###########################################
07 use warnings;
08 use strict;
09
10 use DBI;
11 use CGI qw(:all *table);
12
13 my $USER = "root";
14 my $PASSWORD = "";
15
16 my $dbh = DBI->connect("DBI:mysql:" .
17 "database=serverdaten;host=localhost",
18 $USER, $PASSWORD);
19
20 print header(),
21 start_html(-BGCOLOR => 'white');
22
23 my $sql = <<EOT;
24 SELECT systems.name, subsystems.name,
25 count(*)
26 FROM restarts, systems, subsystems
27 WHERE systems.id = restarts.system AND
28 subsystems.id = restarts.subsys AND
29 DATE_ADD(stamp, INTERVAL 1 DAY) >
30 CURRENT_TIMESTAMP
31 GROUP BY system, subsys
32 EOT
33
34 my $sth = $dbh->prepare($sql);
35 $sth->execute();
36
37 print h1("Last 24 Hours Production " .
38 "System Restarts");
39
40 print start_table({BORDER => 1});
41 print TR(th("System"), th("Unit"),
42 th("Count"));
43
44 while( my($sysname, $subsysname, $count) =
45 $sth->fetchrow_array()) {
46
47 print TR(td($sysname), td($subsysname),
48 td($count));
49 }
50
51 print end_table();
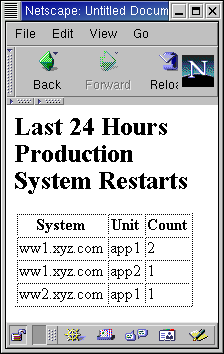 |
| Abbildung 3: Restarts-Anzeige als CGI Skript im Browser |
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |