Aus Webformularen an den Server gesandte Benutzerdaten landen meist in Datenbanken oder zunächst in kommaseparierte Dateizeilen, um sie später mit Tabellenkalkulationen weiterzuverarbeiten. Das heutige Skript löst den Allgemeinfall.
Es gibt Aufgaben, die kehren mit schöner Regelmäßigkeit wieder. Vom Benutzer in ein Webformular eingegebene Daten auf dem Server abzuspeichern, ist eine solche. Meist kommt ein schnell zusammengewürfeltes Perl-Skript zum Einsatz -- wie wär's heute mal mit einer allgemeinen Lösung, die man nur noch entsprechend konfigurieren muss, damit sie entweder kommaseparierte Dateizeilen oder Datenbankeinträge erzeugt?
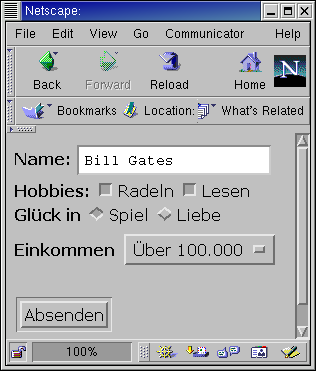
Abbildung 1 zeigt ein typisches Webformular. Neben dem ins Textfeld
eingetragenen String nimmt es die Werte der vom Benutzer ausgewählten
Druck-, Radioknöpfe und Auswahllisten entgegen.
Klickt der Benutzer auf den Absenden-Knopf, schickt der Browser
die Daten an unser heute vorgestelltes CGI-Skript handleform,
welches die Daten entgegennimmt und abspeichert. Gelingt dies,
sendet es einen Redirect zum Browser zurück, der daraufhin
zu einer Dankeschön-Seite verzweigt (/thankyou.html). Geht etwas
schief, hält handleform den Fehler für den Benutzer unsichtbar
in einer Logdatei fest und verzweigt zu einer Fehlerseite
/error.html.
Listing 1 zeigt den zugehörigen HTML-Sourcecode. Soweit nichts neues.
| |
| Abbildung 1: Webformular im Browser. Die eingegebenen Benutzerdaten wandern per CGI-Skript in die Datenbank. |
01 <HTML>
02 <FORM ACTION=/cgi-bin/handleform>
03
04 <B>Name:</B>
05 <INPUT TYPE=text NAME=name>
06
07 <BR><B>Hobbies:</B>
08 <INPUT TYPE=checkbox NAME=hobbies
09 VALUE=radeln>
10 Radeln
11 <INPUT TYPE=checkbox NAME=hobbies
12 VALUE=lesen>
13 Lesen
14
15 <BR><B>Glück in</B>
16 <INPUT TYPE=radio NAME=glueck VALUE=spiel>
17 Spiel
18 <INPUT TYPE=radio NAME=glueck VALUE=liebe>
19 Liebe
20
21 <BR><B>Einkommen</B>
22 <SELECT NAME=einkommen>
23 <OPTION VALUE=e1>Unter 100.000</OPTION>
24 <OPTION VALUE=e2>Über 100.000</OPTION>
25 </SELECT>
26
27 <BR><INPUT TYPE=SUBMIT VALUE=Absenden>
28
29 </FORM>
30 </HTML>
Neu hingegen ist, dass das Skript
handleform sich in seiner Konfigurationssektion
ab Zeile 14 auf beliebige Webformulare anpassen lässt.
Die Namen der HTML-Eingabelemente legt der ab Zeile 34 definierte
@FIELDS-Array fest. Ist ein zugehöriger Wert nicht sehr
aussagekräftig (wie zum Beispiel e1 und e2 für die beiden
zulässigen Werte der Auswahlliste einkommen), darf der
%MAP-Hash ab Zeile 38 unter dem Schlüssel des HTML-Elements (einkommen)
jeweils einen Hash ablegen, der den Kürzeln aussagekräftigere
Begriffe zuordnet (z.B. e1 => "Unter 100.000").
Wie abgedruckt schreibt das Skript die Daten jeder Serveranfrage kommasepariert in die nächste Zeile einer Datei, an die stetig angehängt wird. Abbildung 2 zeigt die CSV-Datei, nachdem sich zwei Benutzer eingetragen haben. Werte, die Leerzeichen oder Kommata enthalten, umrandet der CSV-Treiber mit doppelten Anführungszeichen. Käme in einem der Werte ein doppeltes Anführungszeichen vor, würde es aufgedoppelt.
Kommentiert man allerdings die Zeilen 19
und 20 aus, und aktiviert statt dessen 23 bis 25, kontaktiert
handleform eine auf dem aktuellen Rechner laufende MySQL-Datenbank.
Abbildung 3 zeigt die mit zwei Einträgen gefüllte Tabelle
survey der Datenbank webdata. Die schon in [2] besprochene
DBI-Schnittstelle macht's möglich, eine CSV-Datei genau wie eine
'richtige' Datenbank mit SQL-Befehlen anzusteuern (siehe auch [5]).
 |
| Abbildung 2: Ergebnis als kommaseparierte Spalten in einer CSV-Datei. |
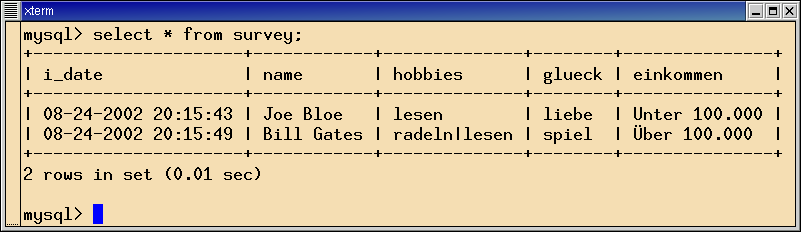 |
| Abbildung 3: ... oder als Tabellenzeilen in einer MySQL-Datenbank. |
Neben
dem praktischen CGI-Modul zum schnellen Erfassen der Eingabeparameter
und DBI für Datenbank- und CSV-Schnittstelle nutzt handleform
auch Log::Log4perl, ein neuartiges Logmodul, das unter
[3] und [4] ausführlich beschrieben steht. CGI-Skripts sollen
schließlich nur generische Fehlermeldungen bringen und den Benutzer
nicht mit Details belästigen. Intern, in einer nur dem Systemadministrator
zugänglichen Datei, hilft hingegen eine möglichst detaillierte
Spurensicherung.
Der init-Befehl ab Zeile 44 konfiguriert den Logger mittels der
aus der Java-Welt stammenden log4j-Sprache dahingehend,
nur Mitteilungen der Priorität WARN oder höher an eine
Logdatei anzuhängen, deren Pfad in Zeile 49 als /tmp/hf.log
definiert wird. Als Logformat legt Zeile 51
Datum Priorität Source-Datei (Zeile) Nachricht
fest. Im Falle einer nicht beschreibbaren CSV-Datei steht da zum Beispiel
2002/08/25 18:57:24 FATAL eg/handleform.csv (60) \
/tmp/data missing/protected at eg/handleform line 138.
während der Browser nur /error.html anzeigt, wo etwas Unverfängliches
wie ``Wegen Wartungsarbeiten vorübergehend geschlossen'' steht.
Zeile 57 holt eine Logger-Instanz, die unter anderem
in Zeile 60, innerhalb eines Pseudo-Signal-Handlers, der
alle die()-Anweisungen des Skripts abfängt, zum Einsatz kommt.
Die fatal()-Methode setzt dort eine Lognachricht der Priorität FATAL
(höher als WARN) an die Logdatei ab.
Nachdem die Nachricht verstaut ist, sorgt
der print-Befehl in Zeile 61 dafür, dass das CGI-Skript
für den Browser eine Redirekt-Anweisung zur Fehlerseite ausgibt
und sich beendet.
Das ist praktisch, denn wann immer im Skript ein Fehler passiert,
rufen wir einfach die() auf, was wegen des Pseudo-Signal-Handlers
in $SIG{__DIE__})
niemals das unschöne Internal Server Error auslöst, sondern
den Fehler in der Logdatei
protokolliert und dem Benutzer /error.html vorlegt.
Die for-Schleife ab Zeile 66 iteriert über alle zugelassenen
Namen für eingehende Parameter und ruft für jeden einzelnen die
param()-Funktion des CGI-Moduls auf, um herauszufinden,
ob dieser auch tatsächlich vorliegt.
CGI-Parameter können auch multiple Werte führen. Stehen in einem
Formular beispielsweise zwei Checkboxen
mit den Werten radeln bzw. lesen, die beide auf den gleichen Namen
hobbies hören, darf der Benutzer beide gleichzeitig auswählen.
In diesem Fall gibt param('hobbies') keinen Einzelwert, sondern
eine Liste mit den Werten radeln und lesen zurück.
Zeile 77 macht daraus radeln|lesen, was hinterher auch
so in der Datenbank liegt. Falls für den Parameter eine
Transformationsanweisung im Hash %MAP vorliegt, nimmt
Zeile 72 diese vor.
init_db() in Zeile 81 ruft die ab Zeile 115 definierte
gleichnamige Funktion
auf, die feststellt, ob die entsprechende Datenbank schon besteht.
Die data_sources() Methode liefert die Namen bestehender
Datenbanken und falls Zeile 123 den in Zeile 16 konfigurierten
Namen schon findet, kehrt
init_db() zurück.
Falls nicht, werden die nötige Schritte eingeleitet, um entweder
die CSV-Datei anzulegen oder
die MySQL-Datenbank zu initialisieren. Im ersten Fall ist nichts
erforderlich, da der CSV-Treiber das Konzept einer virtuellen
``Datenbank'' nicht
kennt. Im Fall von MySQL sorgt der createdb-Aufruf dafür,
dass eine neue, leere Datenbank angelegt wird.
Zeile 83 nimmt Verbindung mit dem generischen Datenbanktreiber auf, hinter dem, je nach Konfiguration, statt eines MySQL-Hobels auch eine nur simple CSV-Datei hängen kann.
init_table() in Zeile 87 ruft die ab Zeile 133 definierte Funktion
auf, die mittels der tables()-Methode des Datenbankhandles
herauszufinden versucht, ob bereits eine entsprechende Tabelle
(in Wahrheit: wirkliche Tabelle oder CSV-Datei) existiert.
Endet einer der Einträge mit dem in Zeile 16 definierten Tabellennamen,
bricht Zeile 144 ab und kehrt zum Hauptprogramm zurück, da die
Tabelle offensichtlich schon existiert.
Wurde hingegen der CSV-Treiber installiert, prüft Zeile 139,
ob das Datenbankverzeichnis $DB_DIR existiert und für den
Webserver-Benutzer (im allgemeinen nobody) zum
Schreiben und Ausführen offen steht.
Falls nicht, schustert Zeile 151 einen SQL-CREATE-Befehl zusammen,
der, über die DBI-Schnittstelle abgeschickt, je nach
Konfiguration eine Tabelle oder eine CSV-Datei erzeugt.
Zu den in @FIELDS definierten Parameternamen kommt
als erste Spalte noch i_date hinzu, die das mit nicedate()
(ab Zeile 104 definiert)
schön formattierte Einfügedatum jedes Eintrags angibt.
Zeile 148 macht alle Spalten der Einfachheit halber vom
Typ VARCHAR(50), die einfach bis zu 50 Zeichen breite Strings aufnehmen.
Zeile 96 definiert den SQL-Befehl, der den neuen Datensatz abspeichert.
Wie in [2] gezeigt, müssen die Werte gegebenenfalls mit quote()
maskiert werden.
Geht alles gut, dirigiert Zeile 101 den Browser zur ``Dankeschön''-Seite
/thankyou.html.
Existiert Datenbank oder Tabelle noch nicht, legt handleform
sie wie gerade gesehen an.
Dies sollte keinesfalls unter Produktionsbedingungen
geschehen, sondern als Bequemlichkeitsfunktion beim ersten
Testaufruf verstanden werden. Kommen sich dabei nämlich
mehrere parallele Prozesse in die Quere, kann's rappeln.
Ist die Datenbank oder die CSV-Datei hingegen einmal angelegt,
sorgen die DBI-Treiber dafür, dass es zu keinen Überlappungen
kommt.
Da SQL keine Spaltennamen duldet, die mit SQL-Schlüsselworten
gleichlauten, verbieten sich im HTML-Formular Feldnamen wie
select, create, insert, aber auch option. Die
Logdatei zeigt solche Fehler jedoch sofort an.
handleform verarbeitet getreu der Devise ``Never trust the user''
nur die in Array @FIELDS definierten Felder. Sendet ein Böswilliger
neue Feldnamen zum Server, werden diese einfach ignoriert. Erfordert
eine Umfrage, dass der Benutzer bestimmte Felder mit einem Wert
versehen muss, löst man diese Aufgabe am besten mit JavaScript. Das
schließt zwar nicht aus, dass der Mann mit dem schwarzen Hut mittels
eines Skripts die Hürde überspringt, aber das wollen wir mal durchgehen
lassen.
Falls im Webformular neue Felder hinzukommen und die alte Datenbank
weiter genutzt werden soll, muss sie vorher um eine Spalte
erweitert werden. In MySQL geht das mit mysqladmin und dem
Befehl ALTER TABLE. In CSV fügt man einfach einen zusätzliche
Spaltennamen ans Ende der ersten Zeite der CSV-Datei ein.
001 #!/usr/bin/perl
002 ###########################################
003 # handleform -- Send FORM data to databases
004 # Mike Schilli, 2002 (m@perlmeister.com)
005 ###########################################
006 use warnings;
007 use strict;
008
009 use CGI qw(:all);
010 use DBI;
011 use Log::Log4perl qw(get_logger);
012
013 ###########################################
014 my $DB_DIR = "/tmp/data";
015 my $DB_HOST = "localhost";
016 my $DB_NAME = "webdata";
017
018 # CSV-File
019 my $DB_DRIVER = "CSV";
020 my $DB_PAR = "f_dir=$DB_DIR";
021
022 # MySQL database
023 #my $DB_DRIVER = "mysql";
024 #my $DB_PAR = "database=$DB_NAME;" .
025 # "host=$DB_HOST";
026
027 my $DB_USER = "root";
028 my $DB_PASSWD = "";
029 my $DB_TABLE = "survey";
030
031 my $THANK_YOU = "/thankyou.html";
032 my $ERROR = "/error.html";
033
034 my @FIELDS = qw(
035 name hobbies glueck einkommen
036 );
037
038 my %MAP = (
039 einkommen => { e1 => "Unter 100.000",
040 e2 => "Über 100.000" },
041 );
042 ###########################################
043
044 Log::Log4perl::init(\ <<'EOT');
045 Log4perl.logger = WARN, File
046 Log4perl.appender.File= Log::Dispatch::File
047 Log4perl.appender.File.layout=\
048 Log::Log4perl::Layout::PatternLayout
049 Log4perl.appender.File.filename=/tmp/hf.log
050 Log4perl.appender.File.layout.Conversion\
051 Pattern=%d %p %F (%L) %m %n
052 EOT
053
054 my $DB_DSN = "DBI:$DB_DRIVER:$DB_PAR";
055 my $DATE = "i_date";
056
057 my $logger = Log::Log4perl::get_logger();
058
059 $SIG{__DIE__} = sub {
060 $logger->fatal(@_);
061 print redirect($ERROR);
062 exit 0 };
063
064 my %val = ();
065
066 for my $field (@FIELDS) {
067 if(defined param($field)) {
068 my @v;
069 for(param($field)) {
070 if(exists $MAP{$field} and
071 exists $MAP{$field}->{$_}) {
072 push @v, $MAP{$field}->{$_};
073 } else {
074 push @v, $_;
075 }
076 }
077 $val{$field} = join '|', @v;
078 }
079 }
080
081 init_db();
082
083 my $dbh = DBI->connect($DB_DSN, $DB_USER,
084 $DB_PASSWD, { RaiseError => 1 } ) or
085 die "Cannot connect to DB";
086
087 init_table($dbh);
088
089 unshift @FIELDS, $DATE;
090 $val{$DATE} = nicedate();
091
092 my $fieldlist = join(",", @FIELDS);
093 my $valuelist = join(",",
094 map { $dbh->quote($val{$_}) } @FIELDS);
095
096 my $sql = qq[
097 INSERT INTO $DB_TABLE ( $fieldlist )
098 VALUES ( $valuelist ) ];
099 my $sth = $dbh->do($sql);
100
101 print redirect($THANK_YOU);
102
103 ###########################################
104 sub nicedate {
105 ###########################################
106
107 my ($s,$mi,$h,$d,$mo,$y) = localtime();
108
109 return sprintf(
110 "%02d-%02d-%d %02d:%02d:%02d",
111 $mo+1, $d, $y+1900, $h, $mi, $s);
112 }
113
114 ###########################################
115 sub init_db {
116 ###########################################
117
118 my($drh) = DBI->install_driver(
119 $DB_DRIVER);
120 my @dbs = $drh->data_sources(
121 { 'f_dir' => $DB_DIR } );
122 @dbs = () unless defined $dbs[0];
123 return if grep { /\b$DB_NAME/ } @dbs;
124
125 return if $DB_DRIVER eq "CSV";
126
127 $drh->func("createdb", $DB_NAME,
128 $DB_HOST, $DB_USER, $DB_PASSWD,
129 "admin");
130 }
131
132 ###########################################
133 sub init_table {
134 ###########################################
135 my $dbh = shift;
136
137 if($DB_DRIVER eq "CSV") {
138 die "$DB_DIR missing/protected" if
139 !-d $DB_DIR or !-w _ or !-x _;
140 }
141
142 my @tables = $dbh->tables();
143
144 return if grep {
145 $_ =~ /\b$DB_TABLE$/ } $dbh->tables();
146
147 my $defs = join ",", map {
148 "$_ VARCHAR(50)" } $DATE, @FIELDS;
149
150 $dbh->do(qq[
151 CREATE TABLE $DB_TABLE ( $defs ) ]);
152 }
Aus dem verwendeten Webformular sind zunächst die Parameternamen
zu extrahieren und Zeile 35 von handleform entsprechend anzupassen.
Sollen einige Parameter unter unterschiedlichen Namen abgespeichert
werden, legt dies Zeile 39 fest.
Die Wahl zwischen CSV und MySQL erfolgt durch aus- bzw. entkommentieren
der Zeilen 19-20 bzw. 23-25. Die Parameter
$DB_DIR (Verzeichnis der CSV-Datei), $DB_HOST (MySQL-Hostname),
$DB_NAME (Name der MySQL-Datenbank),
$DB_TABLE (Name der MySQL-Tabelle) sind an die lokalen Anforderungen
anzupassen.
Als Zusatzmodule finden Log::Log4perl (das wiederum Log::Dispatch
und Param::Validate braucht)
CGI, DBI, DBD::mysql (MySQL-Treiber),
und DBD:CSV (CSV-Treiber) Einsatz. Eine CPAN-Shell holt nicht nur
die Module vom Netz, sondern löst auch noch die Abhängigkeiten auf:
perl -MCPAN -eshell
cpan> install Log::Log4perl
cpan> install DBD::mysql
cpan> install DBD::CSV
handleform muss ausführbar ins cgi-bin-Verzeichnis des Webservers.
Die in den Zeilen 31 und 32 definierten relativen URLs müssen
auf gültige HTML-Seiten zeigen. Absolute URLs (http://blabla)
funktionieren natürlich auch. Die in Zeile 49 festgelegte Logdatei
muss vom Benutzer des Webservers (meist nobody) beschreibbar sein.
Gleiches gilt für die CSV-Datei und das Verzeichnis, in dem sie liegt.
Ist MySQL im Spiel, muss der Benutzernamen ($DB_USER)
und das Passwort ($DB_PASSWD) stimmen.
Gestaltet massenhaft Webumfragen!
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |