Ein kommandozeilenbasierter Frontend kategorisiert und archiviert Schnappschüsse und stöbert in digitalen Bildersammlungen.
Als ich entdeckte, dass man unter Linux ganz einfach auf die Bilder einer per USB angestöpselten digitalen Kamera zugreifen kann, nahm ich mir vor, endlich Ordnung in meine etwa 5000 privaten Schnappschüsse zu bringen, die seit einigen Jahren in loser Ordnung als JPGs auf meiner Festplatte herumlungern.
Das Problem ist freilich, die Bilder konsequent zu beschriften. Wer aus dem Urlaub mit 500 digitalen Fotos heimkommt, setzt sich nicht hin, um alle mit Texten wie ``Ich mit Blumenkette neben dem Mietauto auf Hawaii 2002'' zu versehen. Vielmehr landen alle 500 unbeschriftet in einem Verzeichnis und vier Wochen später hat man sie vergessen. Sucht man nach Jahren die Hawaii-Fotos von 2002, geht die Sucherei los.
Programme wie ``iphoto'' auf dem Mac und das brandheiße ``Photoshop Album'' von Adobe sind zwar ganz brauchbar, doch grafische Oberflächen von proprietären Produkten sind schnell ausgereizt -- üblicherweise dauert es nur wenige Tage bis ich an die Grenzen stoße und lautstark eine programmierbare Schnittstelle fordere.
Über diese und die nächste Ausgabe des Snapshots verteilt bauen wir deshalb eine programmierbare Bilderverwaltung mit allen Schikanen, die man auch (aber nicht nur) von der Kommandozeile aus bedienen kann, um Abfragen in alter Unix-Tradition mit Pipes zu verknüpfen und zu filtern, dass es nur so schnackelt.
Als erstes stellt sich die Frage: Wie bezeichnet man die Bilder eindeutig, welche ID weist man jedem zu? Nach einigem Herumprobieren fand ich es am einfachsten, das genaue Datum herzunehmen, an dem ein Bild aufgenommen wurde:
2002-03-01_22:13:01
2002-03-01_23:22:17
...
2003-02-13_11:07:13
Voraussetzung dafür ist allerdings, dass man das Datum an der
Kamera richtig eingestellt hat und nicht mehr als ein Bild pro Sekunde
schießt.
Digitale Kameras speichern die sekundengenaue Information in entsprechenden
Tags in der Bilddatei ab,
von wo man sie einfach mit Modulen wie Image::Info
extrahieren kann. So kriegt man auch Bilder, die aus Versehen in
der falschen Reihenfolge archiviert wurden oder gar in einem
alten Unterverzeichnis verstaubten, leicht wieder geordnet.
Außerdem lässt sich so blitzschnell feststellen, ob ein unbekannt
aussehendes Bild schon in der Datenbank liegt oder nicht, da das Datum
ein eindeutiger Stempel ist.
Zur Beschriftung eignen sich Text-Tags, die man auf einen Schlag gleich einem Schuhkarton voll Bildern zuordnen kann -- das spart Zeit. Ein Bild kann beliebig viele Tags erhalten, ein und dasselbe Tag kann vielen Bildern zugeordnet sein.
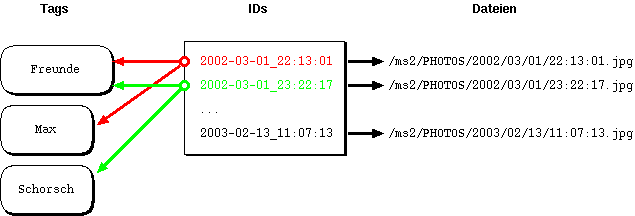
Dabei liegen die Bilder in per Jahr, Monat und Tag aufgeteilten Unterverzeichnissen auf der Festplatte und die Tag-Informationen in einer MySQL-Datenbank. Abbildung zeigt die praktische Umsetzung mit Tags die (beispielhaft) in Ober- und Unterkategorien aufgeteilt sind.
| |
| Abbildung 1: Bild 2002-03-01_22:13:01 gehört zur Kategorie "Freunde" und ebenfalls zu "Max", Bild 2002-03-01_23:22:17 ist ebenfalls das Tag "Freunde" zugeordnet, es gehört aber zusätzlich zur Kategorie "Schorsch". |
idb für Image Database heisst der heute vorgestellte
Kommandozeilen-Frontend für das neue System.
Ein paar Beispiele gefällig? Gerade aus den Bahamas zurückgekommen,
hängen wir die Kamera an die Linuxkiste und tippen
$ idb --import --tag "Bahamas 2003" /mnt/cam/dcim/100_fuji
und schon wandern alle JPGs aus dem Kameraverzeichnis 100_fuji
in die Datenbank. Liegen
diese stattdessen in einigen Verzeichnisse auf dem Laptop, ist auch
das kein Problem, und sogar die
länglichen Optionen können verkürzt werden:
$ idb -i -t "Tirol 2002" /samba/laptop/fotos/*
liest alle per Kommandozeile gefundenen Ordner und die darin liegenden Dateien ein und beschriftet alle Bildchen mit dem Tag ``Tirol 2002''. Gerade irgend ein altes JPG gefunden? Obwohl Tags später hilfreich sind, zwingt uns niemand dazu, gleich eines anzugeben -- also vorerst mal nur archivieren:
$ idb -i uralt.jpg
2002-03-01_23:22:17
Jeder --import-Aufruf gibt die neuen ID(s) der eingespeicherten
Fotos zurück.
Auch nachträglich lässt sich noch ein Tag an ein Bild hängen,
wenn die ID angegeben wird:
$ idb -t "Freunde" 2002-03-01_23:22:17
Statt der ID geht auch der Name der Datei,
denn idb wird dessen Zeitstempel auslesen, zur Datenbank gehen,
die ID ermitteln und den Tag anhängen:
$ idb -t "Max" uralt.jpg
Und auch mehr als ein ``Tag'' pro Bild sind natürlich erlaubt, im vorliegenden
Fall wurde das Bild sowohl mit ``Freunde'' als auch ``Max''
verknüpft. Die List-Funktion zeigt nun für uralt.jpg zwei Tags an:
$ idb -l uralt.jpg
uralt.jpg: Freunde, Max
Um, umgekehrt, die Bilder zu einem gegebenen Tag
aus der Datenbank hervorzukitzeln, dient die Option --search,
abgekürzt -s:
$ idb -s "Max"
2002-03-01_23:22:17
Um statt der ID den Pfad zur Bild-Datei zu erhalten, dient die Option -p,
und als reguläre Ausdrücke sind SQL-Formate erlaubt:
$ idb -s "Freu%" -p
/store17/pics/2002/03/01/23:22:17.jpg
Wenn's zu viele Ergebnisse hagelt, lässt sich idb mit -g
(--grep) auch als Filter verwenden. Der Aufruf
$ idb -s "%Italien%" | idb -g "%Meer%" -p
/store17/pics/2001/07/2001-07-07_12:21:15.jpg
filtert aus allen irgendwie mit
``Italien'' gekennzeichneten Bildern nur diejenigen heraus,
die ein Tag führen, in dem ``Meer'' vorkommt.
Durch die Pipe kommen zeilenweise passende IDs geflogen, die der
zweite Aufruf von idb am anderen Ende der Pipe gierig aufschnappt
und weiteren Filterkriterien unterwirft.
Die -g-Option
gibt, im Gegensatz zu -s an,
dass idb nicht auf Bildern in der Datenbank operiert,
sondern auf den per ID durch STDIN hereinkommenden.
Und, natürlich kann man ein versehentlich getaggtes Bild wieder von der zugeordneten Kategorie befreien. Der Aufruf
$ idb -u "Max" 2002-03-01_23:22:17
nimmt den ``Max'', aber belässt die ``Freunde''-Kategorie.
idb zieht eine Reihe von Zusatzmodulen herein, die allesamt leicht
vom CPAN zu holen und zu installieren sind: Log::Log4perl für Warn-
und Fehlermeldungen,
Image::Info, um die Tag-Informationen aus JPG-Bildern zu extrahieren,
File::Path zum Erzeugen beliebig tiefer Verzeichnisse mittels mkpath(),
File::Copy zum Kopieren von Dateien, das weiter unten besprochene
Getopt::Long, sowie Pod::Usage, um dem Benutzer
die als POD angehängte Bedienungsanleitung mittels pod2usage()
um die Ohren zu schlagen,
falls er ungültige Optionen eingibt.
Weiter nutzt es CameraStore, die Datenbankschnittstelle, die im
nächsten Snapshot detailliert besprochen wird.
idb speichert Informationen auf zweierlei Art: Image-Dateien
wandern in Jahr/Monat/Tag-spezifische Verzeichnisse unterhalb
$IMG_FILE_DIR (Zeile 8 in idb).
Ist dieses, wie im Skript auf /ms2/PHOTOS gesetzt,
kopiert idb das Bild mit der ID 2002-03-01_23:22:17 einfach
nach
/ms2/PHOTOS/2002/03/01/23:22:17.jpg
und erzeugt die dafür notwendigen Unterverzeichnisse automatisch.
Die Datenbank erhält hierüber folgende Informationen: Die ID des
Bildes, den Pfad, unter dem es abgespeichert wurde und dazu etwaige
Tag-Informationen, die dem Bild mittels der Option -t angeheftet wurden.
Kommen später weitere Bilder in beliebiger Reihenfolge hinzu, sortiert sie das Verfahren automatisch in die richtige Aufnahmereihenfolge. Auch kann man schön mit einem Browser oder Viewer durch die einzelnen Tage streunen und das Geschehen verfolgen ...
Ein vielfältiges Programm wie idb muss eine Vielzahl von
Kommandozeilenoptionen verstehen. Zum Glück erleichtert
Getopt::Long vom CPAN die Arbeit. Man gibt, wie in den Zeilen
29 bis 37 im Listing idb gezeigt, einfach die ausgeschriebenen
Optionen (z.B. --list) an, definiert, ob die jeweilige
Option für sich steht oder ein String-Argument erwartet (=s) und weist
ihr jeweils eine Referenz auf einen Skalar zu. Dieser enthält dann bei
binären Werten entweder einen wahren (Option gesetzt) oder falschen Wert
(Option nicht gesetzt). Bei String-Optionen steht der auf der
Kommandozeile zugeordnete Wert drin. Falls eine eindeutige Zuweisung
möglich ist, versteht Getopt::Long sofort sinnvolle Abkürzungen,
also zum Beispiel -l statt --list, wenn keine andere Option
mit -l anfängt.
Die in den Zeilen 18, 20 und 22 vorcompilierten regulären Ausdrücke
$ID_REGEX, $TS_REGEX und $PIC_REGEX dienen später dazu,
richtige IDs, Datumsstempel und Dateinamen
von JPEG-Bildern als solche zu erkennen und mittels Klammern
interessante Informationen zu extrahieren, die später als $1, $2, usw.
vorliegen.
Da das Skript das Modul Log::Log4perl zur Ausgabe von Warn- und Fehlermeldungen ausgibt, initialisiert Zeile 24 es auf dem WARN-Level, leitet Meldungen nach STDERR um und legt das Format mit ``%p %m%n'' so fest, dass der Meldung mit Zeilenumbruch auch die Priorität (WARN, ERROR etc.) beiliegt.
Zeile 40 initialisiert ein CameraStore-Objekt, die Schnittstelle
zur Datenbank, deren Methoden später genutzt werden, um den Inhalt
zu manipulieren.
Wurde --search angewählt, möchte der Benutzer offensichtlich nach
Tag-Begriffen in der Datenbank stöbern. Dann ist $search gesetzt
und Zeile 42 verzweigt und zur in Zeile 43 ausgeführten
Datenbankmethode, die im Erfolgsfall eine Liste mit Image-IDs
zurückliefert, die wiederum die nachfolgende print-Funktion
einfach Zeilenweise auf STDOUT ausgibt. So können auf der
Kommandozeile nachgeschalte Filter sie nutzen, um ihrerseits das
Ergebnis zu verfeinern. Zeile 46 bricht nach getaner Arbeit das
Programm ab, der Rest von idb beschäftigt sich mit entweder
via Kommandozeile oder STDIN hereinkommenden Dateien und IDs.
Hierzu holt sich Zeile 49 in $in einen Funktionspointer,
den die ab Zeile 144 definierte Funktion get_input_sub() zurückliefert.
Es geht darum, einen Pointer zu einer Funktion zu erhalten, die
bei jedem Aufruf die nächste zu bearbeitende Datei (oder ID) liefert,
unabhängig davon, wie der Benutzer dies auf der Kommandozeile
festlegte. Egal ob Dateien oder Verzeichnisse hereinkommen
(letztere werden transparent ausgelesen), und ebenfalls unabhängig
davon ob via @ARGV oder STDIN: Die von get_input_sub als
Referenz zurückgegebene Funktion gibt bei jedem Aufruf die
nächste zu bearbeitende Datei (oder ID) zurück.
Diese etwas unkonventionelle Technik wird durch eine sogenannte
Closure realisiert, die die in Zeile 146 definierte lexikalische
Variable @items einschließt und mit Dateien oder Verzeichnissen
füllt. Zeile 157 gibt dann eine Referenz auf eine Funktion zurück,
die den Array @items einsperrt und damit bei jedem Aufruf Zugriff auf
dessen Werte hat. Eine Art Instanzvariable für Arme.
Ist der nächste vorliegende Wert ein Verzeichnis, löschen
die Zeilen 160 und 161 das entsprechende Arrayelement und schaufeln
statt dessen (unter Umständen viele) in ihm liegende Bilddateien,
die auf den regulären Ausdruck $PIC_REGEX passen, nach.
Zurück ins Hauptprogramm ab Zeile 51: Die while-Schleife erhält
durch Ausführen der als Referenz vorliegenden Closure-Funktion
$in->() und dem gerade beschriebenen Mechanismus eine Bilddatei
nach der anderen. Wurde das --import-Flag gesetzt, ruft Zeile
54 die ab Zeile 82 definierte Funktion add_file auf und übergibt
ihr eine Referenz auf das CameraStore-Objekt, den Dateinamen
und ein eventuell gesetztes Tag. add_file wird dann in Zeile
86 die Funktion file_info aufrufen, die das Bild öffnet,
das Datum extrahiert und die daraus resultierenden Werte für
$stamp (ID), $dir (das Bildverzeichnis .../JJ/MM/DD) und
$file (den Bildnamen SS:MM:ss.jpg)
als Liste ans Hauptprogramm zurückreicht.
file_info() nutzt hierzu die ab Zeile 128 definierte
Funktion image_date(), die ihrerseits das Modul Image::Info
vom CPAN nutzt, um die Datumsinformation aus dem von der
digitalen Kamera aufgenommenen JPG-Bild herauszuholen.
In $TS_REGEX liegt der reguläre Ausdruck, der auf den in meiner
Fuji Finepix verwendeten Zeitstempel (Format ``JJ:MM:TT HH:mm:ss'')
passt -- für andere Kameras ist der eventuell entsprechend zu ändern.
Da er Klammern enthält, kann Zeile 140 auf die in
Zeile 136 ermittelten Teilkomponenten per $1, $2, usw. zugreifen.
Wieder zurück zum Hauptprogramm: Zeile 58 transformiert nun
jedes Bild, das noch als Datei vorliegt, in die entsprechende
ID, auch wiederum mittels file_info(), von dem sie nur das
erste Argument auffängt und den Rest ignoriert.
Falls von dort nichts Gescheites zurückkommt, liegt das Bild
offensichtlich nicht in der Datenbank, worauf idb einen Fehler
meldet und mit next zum nächsten Bild weiterspringt.
Tags zu Bildern hinzuzufügen und wieder zu entfernen ist eine einfache Aufgabe für die Datenbankschnittstelle, die Zeilen 66 und 68 rufen einfach die entsprechenden Methoden auf und übergeben ihnen diese ID des entsprechenden Bildes und den Tagwert.
Ist die --grep-Option aktiv, gibt Zeile 70 die ID des
gerade untersuchten Bildes aus, falls die Datenbankschnittstelle
mittels search_tag() bestätigt, dass ihm das Tag tatsächlich
anhaftet. Falls nicht, gibt sie nichts aus und der nächste Filter
wird die ID nie zu Gesicht bekommen.
Die --list-Option schließlich lässt idb in den if-Block
ab Zeile 73 springen, den Namen des Bildes ausgeben und die von
der Datenbank mit list_tags() ermittelten Tags
kommasepariert danebenstellen. Fertig!
Folgende Kommandos (unter root) schalten unter einem standardmäßig
ausgelieferten RedHat-8.0-System das USB-Modul zu und mounten die
Kamera unter /mnt/cam:
# modprobe usbcore
# modprobe usb-uhci
# modprobe usb-storage
# mount -t auto /dev/sda1 /mnt/cam
Um die gerade auf der Kamera gespeicherten Bilder in die Image-Datenbank zu importieren, tippt man (am Beispiel einer Fuji Finepix) einfach
idb -i -t "Erste Bilder" /mnt/cam/dcim/100_fuji
und mit dem nächsten Mal vorgestellen CameraStore.pm
kann's dann losgehen. Bis denn!
001 #!/usr/bin/perl
002 ###########################################
003 # Mike Schilli, 2003 (m@perlmeister.com)
004 ###########################################
005 use warnings;
006 use strict;
007
008 my $IMG_FILE_DIR = "/ms2/PHOTOS";
009
010 use CameraStore;
011 use Log::Log4perl qw(:easy);
012 use Image::Info qw(image_info);
013 use File::Path;
014 use File::Basename;
015 use File::Copy;
016 use Getopt::Long;
017 use Pod::Usage;
018
019 my $ID_REGEX = qr#^(\d{4})-(\d\d)-(\d\d)
020 _(\d\d):(\d\d):(\d\d)$#x;
021 my $TS_REGEX = qr#^(\d{4}):(\d\d):(\d\d)\s
022 (\d\d):(\d\d):(\d\d)$#x;
023 my $PIC_REGEX = qr#(\.jpg)$#i;
024
025 Log::Log4perl->easy_init(
026 { file => 'stderr',
027 level => $WARN,
028 layout => "%p %m%n"});
029
030 GetOptions(
031 "import" => \my $import,
032 "tag=s" => \my $tag,
033 "untag=s" => \my $untag,
034 "filter" => \my $filter,
035 "list" => \my $list,
036 "xlink" => \my $xlink,
037 "grep=s" => \my $grep,
038 "search=s" => \my $search,
039 "paths" => \my $paths) or
040 pod2usage();
041
042 my $db = CameraStore->new();
043
044 if($search) {
045 for($db->search_tag($search, $paths)) {
046 if($xlink) {
047 symlink $_, basename($_) or warn "Cannot symlink $_ ($!)";
048 }
049 print "$_\n";
050 }
051 exit 0;
052 }
053
054 my $in = get_input_sub();
055
056 while($_ = $in->()) {
057
058 if($import) {
059 add_file($db, $_, $tag);
060 next;
061 }
062
063 my($id) = (-f) ? file_info($_) : $_;
064 unless(defined $id and
065 $id =~ /$ID_REGEX/) {
066 ERROR "Image $_ not in DB";
067 next;
068 }
069
070 if($tag) {
071 $db->add_tag($tag, $id);
072 } elsif($untag) {
073 $db->delete_tag($untag, $id);
074 } elsif($grep) {
075 print "$_\n" for
076 $db->search_tag($grep,
077 $paths, $id);
078 } elsif($list) {
079 print "$_: ", join(', ',
080 $db->list_tags($id)), "\n";
081 } else {
082 pod2usage("Options error");
083 }
084 }
085
086 ###########################################
087 sub add_file {
088 ###########################################
089 my($db, $ofile, $tag) = @_;
090
091 my($stamp, $dir, $file) =
092 file_info($ofile);
093
094 return undef unless defined $file;
095
096 if(!-d $dir) {
097 mkpath($dir) or
098 LOGDIE "Cannot mkpath $dir";
099 }
100
101 copy($ofile, "$dir/$file") or
102 LOGDIE "$ofile > $dir/$file failed";
103
104 $db->add_image($stamp,
105 "$dir/$file", $tag);
106 print "$stamp\n";
107 }
108
109 ###########################################
110 sub file_info {
111 ###########################################
112 my($ofile) = @_;
113
114 my ($suffix) = ($ofile =~ $PIC_REGEX);
115
116 unless($suffix) {
117 ERROR "Unknown image type: $ofile";
118 return undef;
119 }
120
121 my($y, $m, $d, $h, $mi, $s) =
122 image_date($ofile);
123 return undef unless defined $s;
124
125 my $stamp = "$y-$m-${d}_$h:$mi:$s";
126 my $dir = "$IMG_FILE_DIR/$y/$m/$d";
127 my $file = "$h:$mi:$s$suffix";
128
129 return($stamp, $dir, $file);
130 }
131
132 ###########################################
133 sub image_date {
134 ###########################################
135 my($file) = @_;
136
137 my $info = image_info($file);
138
139 if ($info->{error} or
140 ! exists $info->{DateTime} or
141 $info->{DateTime} !~ $TS_REGEX) {
142 WARN "No timestamp from $file";
143 return undef;
144 }
145 return($1, $2, $3, $4, $5, $6);
146 }
147
148 ###########################################
149 sub get_input_sub {
150 ###########################################
151 my @items = ();
152
153 if(@ARGV) {
154 push @items, @ARGV;
155 } else {
156 while(<STDIN>) {
157 chomp;
158 push @items, $_;
159 }
160 }
161
162 return sub {
163 if(@items and -d $items[0]) {
164 my $dir = shift @items;
165 unshift @items,
166 grep /$PIC_REGEX/, <$dir/*>;
167 }
168 return shift @items;
169 };
170 }
171
172 __END__
173
174 =head1 NAME
175
176 idb - Image database client
177
178 =head1 SYNOPSIS
179
180 # Import and tag
181 idb -i -t tag [file|dir] ...
182 # Filter files and tag
183 ls *.jpg | idb -t tag
184 # DB search for tags, print paths
185 idb -s search_pattern -p
186 # Grep for tags in files
187 idb -g search_pattern [file|dir] ...
188 # List files/tags
189 idb -l [file|dir] ...
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |