
Eine aktiv genutzte und mit den neuesten CPAN-Modulen ausgestattete Perl-Installation hat schnell mal ein paar tausend Manualseiten. Höchste Zeit, einen Index mit Volltextsuche darauf zu definieren.
In welcher Perl-FAQ stand nochmal erklärt, warum Fließkommazahlen manchmal so komisch gerundet werden? Freilich, man kann mit
perldoc -q floating
alle einer Perl-Distribution beiliegenden FAQs nach dem Stichwort ``floating'' durchsuchen, aber so findet man nichts, denn die richtige Frage heisst
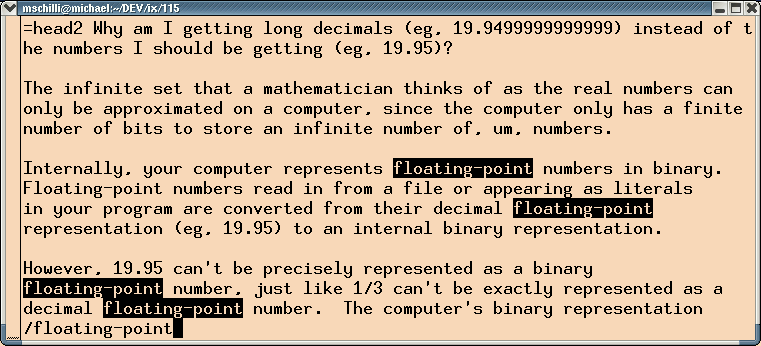
Why am I getting long decimals (eg, 19.9499999999999)
instead of the numbers I should be getting (eg, 19.95)?
und die enthält kaum Stichworte, auf die man von allein kommen würde.
Mit dem heute vorgestellten Skript perldig wird das einfacher,
denn es wühlt sich durch alle Manualseiten einer Perl-Distribution,
einschließlich der installierter Zusatzmodule, und definiert einen
Index für eine später laufende Volltextsuche von der Kommandozeile,
der man dann Dinge wie
perldig floating-point AND approximate AND real number
in Auftrag geben kann, worauf diese ein Zahlenmenü aller Dokumente,
die eine Kombination der angegebenen Begriffe enthalten
(Abbildung 1), zur Auswahl stellt. Wählt man eines davon aus,
landet man im Pager less, um die Suche fortzusetzen
(Abbildung 2).
| |
| Abbildung 1: |
 |
| Abbildung 2: |
Als Indizierer verwenden wir heute mal SWISH-E, ein von der UC
Berkeley aufgepepptes und GPL-lizensiertes Produkt eines 1994 von
Kevin Hughes geschriebenen Such-Engines namens SWISH. Es
besteht nach der Installation aus einem ausführbaren Programm
swish-e und einer Bibliothek mit der Perl-Schnittstelle SWISH::API.
Um die Dokumente eines Dateibaums für eine spätere schnelle Volltextsuche
zu indizieren, ruft man, wie in [3] genau erläutert, swish-e
normalerweise von der Kommandozeile auf:
swish-e -c mytree.conf
wobei mytree.conf eine Konfigurationsdatei etwa folgenden Inhalts ist:
# mytree.conf
IndexDir /dokumenten/baum
IndexFile /pfad/mytree.index
UseStemming Yes
IndexDir gibt den Pfad zur Wurzel des zu indizierenden Dokumentenbaums
an, IndexFile ist die von swish-e erzeugte Index-Datei
(genaugenommen entstehen zwei Dateien, mytree.index
und mytree.index-prop). Die UseStemming-Option bestimmt, dass
swish-e die Wörter auf ihren Stamm reduziert, bevor es sie in den
Index übernimmt, aus floating wird so float. Sucht später jemand
nach floater, wird swish-e auch dieses Wort auf float reduzieren und
das Dokument finden, das vorher floating enthielt. Zuverlässig funktioniert
das allerdings nur mit Dokumenten in englischer Sprache.
Statt einem zu indizierenden Pfad nimmt IndexDir auch gerne ein
ausführbares Programm entgegen:
# mytree.conf
IndexDir some_script
IndexFile /pfad/mytree.index
UseStemming Yes
Ruft man den Indizierer dann mit
swish-e -c mytree.conf -S prog
auf, führt er some_script aus und schnappt aus dessen Standardausgabe
mit Headern versehene Dateien zur Indizierung auf:
Path-Name: datei_name
Document-Type: TXT*
Content-Length: 12345
Text ...
Als Dokumenttypen versteht es TXT* (Text), HTML* und XML*. Die
Länge des nach doppeltem Zeilenumbruch folgenden Textes steht
nach Content-Length.
Das heute vorgestellte Perlskript perldig
schlägt gleich drei Fliegen mit einer Klappe:
-u (für update) aufgerufen, erzeugt es eine wie
oben gezeigte Konfigurationsdatei und setzt als IndexDir sich selbst
(ohne -u-Option).
swish-e-Suche an, die eine Liste
passender Dokumente zurückliefert.
Als erstes Zusatzmodul zieht Listing perldig das Core-Modul
Config.pm herein, das
mit den Hasheinträgen installsitearch, installsitelib,
installarchlib und installprivlib die Pfade zu den installierten
Modulen der aktuellen Perl-Installation angibt. Die arch-Teile
geben jeweils die Prozessor-Architektur-abhängigen Pfade (z.B.
i686-linux) an, site deutet auf den site_perl-Zweig.
installprivlib ist typischerweise /usr/lib/perl5/5.8.0
auf einem Linux-System mit Perl 5.8.0.
Die Reihenfolge dieser Einträge ist später wichtig, da perldig
sie der Reihe nach verwenden wird, um absolute Modulpfade relativ
zu formen. Der längste Pfad sollte als erstes kommen, da so
der einfache Stringersetzungsmechanismus am besten arbeitet.
Die aus
Getopt::Std exportierte Funktion getopts()
untersucht Kommandozeilenoptionen, von denen
nur -u akzeptiert und, falls vorhanden, aus @ARGV
entfernt wird. Die if-Logik ab Zeile 34 steuert die passende
der drei oben beschriebenen erledigten Missionen an: Den
Index auffrischen (update_index),
eine Suche durchführen (search) oder alle Moduldateien suchen
und mit Headern hinausposaunen (stream_files).
Die Zeilen 22 und 24 zeigen mit glob "~/..." portabel auf das
Heimatverzeichnis des aktuellen Benutzers.
In search() ab Zeile 43 entsteht zunächst ein neues
Objekt der Klasse SWISH::API, dessen Methode AbortLastError
das Programm mit einer Fehlermeldung abbricht, falls die
Error()-Methode
an der kurz vorher ausgeführten Aktion etwas zu bemängeln hat.
Zeile 52 überreicht der Query()-Methode einen String mit
den aneinandergereihten und durch Leerzeichen getrennten
Suchwörtern, die dann ein Ergebnisobjekt zurückgibt, dessen
Hits()-Methode die Anzahl der swish-e-Treffer anzeigt.
Die while-Schleife ab Zeile 68 iteriert dann mit NextResult()
durch alle Ergebnisse, die wiederum in sogenannte Properties
aufgeteilt sind. Eines davon, swishdocpath, gibt den Pfad zur
Datei an, in der SWISH-E einen Treffer verbuchte.
Zeile 72 löscht mit
$path =~ s|^$_/|| for @DIRS;
unscheinbar alle absoluten Pfade am Anfang des gefundenen
Dateipfades -- am Ende bleibt etwas wie Log/Log4perl.pm übrig,
obwohl der ganze Pfad vielleicht
/usr/lib/perl5/5.8.0/Log/Log4perl.pm
lautete. Im Hash %map merkt perldig sich aber die Zuordnung
von relativen zu absoluten Pfadnamen, damit es später, falls
der Benutzer diese Datei auswählt, auch schnell dorthinspringen
kann.
Ab Zeile 79 steht ein neues Konstrukt, das das Modul
Shell::POSIX::Select von Tim Maher mit Haken und Ösen nach
Perl eingeschleust hat: Ein Port der nur alten Unix-Dinosauriern
bekannten Shell-Schleife select, die den Benutzer aus
einer Liste von Einträgen per Nummer einen auswählen lässt.
Die in Zeile 77 reingezwängte our-Anweisung deklariert ein
paar von Shell::POSIX::Select hinterrücks eingeschleuste
(hust, hust!) Variablen und macht das Ganze auch im
use strict-Modus gesellschaftsfähig.
Der system()-Aufruf in Zeile 80 ruft das less-Programm auf
und zeigt so den Text der gefundenen Datei an. last in Zeile
81 bricht die select-Schleife ab, andernfalls würde sie
eine neue numerische Eingabe erwarten.
Die ab Zeile 86 definierte Funktion stream_files() durchstöbert
die Datei-Hierarchien, ausgehend von den in @DIRS festgelegten
Verzeichnissen. Zum Einsatz kommt das Modul File::Find::Rule,
das ein bisschen anders als das allseits bekannte File::Find
funktioniert. Statt einer Callback-Funktion definiert es einen
Satz von hintereinandergehängten Filtern auf gefundene
Dateisystemeinträge und lässt nur durch, was alle Filter passiert.
Die file()-Regel in Zeile 89 beschränkt die Auswahl auf Dateien
(keine Verzeichnisse oder Links), Zeile 90 wirft alles raus,
was nicht auf .pod oder .pm endet, und Zeile 91 lässt
den Reigen in den in @DIRS definierten Verzeichnissen starten.
Die while()-Schleife ab Zeile 93 ruft immer wieder die
match()-Methode des File::Find::Rule-Objekts auf und
iteriert so über alle gefundenen Moduldateien.
Da wir nur deren Text-Inhalt und nicht ihren POD-Markup indizieren
wollen, kommt ein Pod::Simple::TextContent-Parser zum Einsatz.
Dessen output_string()-Methode definiert den String, in
dem der Parser seine Ausgabe ablegt. parse_file() in Zeile
99 startet den Parser, der sich durch die gerade gefundene
Modul-Datei wühlt.
Die print-Anweisung in Zeile 102 gibt den von SWISH-E geforderten
Header für das folgende Dokument aus, dessen Byte-Länge in Zeile
100 mittels length() ermittelt wurde.
Die ab Zeile 110 definierte Funktion update_index() legt
frecherweise gleich eine Konfigurationsdatei für swish-e an,
falls diese noch nicht existiert.
Anschließend sorgt der system()-Aufruf in Zeile 122 dafür,
dass swish-e anspringt und einen neuen Index -- gemäß den
Einstellungen in der Konfigurationsdatei -- erstellt. Das kann,
je nach Anzahl der zu indizierenden Dokumente, ein paar Minuten
dauern, deswegen gibt Zeile 94 den Namen jedes gerade bearbeiteten
Dokuments auf STDERR aus. Wer perldig -u per cronjob laufen
lässt, sollte diese Ausgaben in den Abfall schicken, etwas
wie
0 4 * * * /pfad/perldig -u >/dev/null 2>&1
wäre um vier Uhr morgens angebracht.
perldig kann auch nach Kombinationen von Wörtern suchen, die man
einfach mit AND und OR verknüpft:
perldig local AND '"input record"'
Falls man nach aus mehreren Wörtern zusammengesetzten Begriffen sucht,
muss man die doppelten Anführungszeichen, wie oben gezeigt, mit einfachen
Quotes schützen, damit sie auch bei swish-e ankommen nicht
der Shell zum Opfer fallen. Auch Klammern brauchen Schutz:
perldig "(override OR overload) AND object-oriented"
gibt alle OO-Dokumente, in denen entweder von overriding oder
overloading die Rede ist, zurück.
001 #!/usr/bin/perl
002 ###########################################
003 # perldig
004 # Mike Schilli, 2003 (m@perlmeister.com)
005 ###########################################
006 use warnings;
007 use strict;
008
009 use Config;
010 use SWISH::API;
011 use Shell::POSIX::Select;
012 use File::Basename;
013 use Getopt::Std;
014 use File::Path;
015 use File::Find::Rule;
016 use Pod::Simple::TextContent;
017
018 our $LESS = "less";
019 our $SWISH = "swish-e";
020
021 our $IDX_FILE =
022 glob "~/.perldig/perldig.index";
023 our $CNF_FILE =
024 glob "~/.perldig/perldig.conf";
025
026 our @DIRS = ($Config{installsitearch},
027 $Config{installsitelib},
028 $Config{installarchlib},
029 $Config{installprivlib},
030 );
031
032 getopts("u", \my %opts);
033
034 if($opts{u}) {
035 update_index();
036 } elsif(@ARGV) {
037 search(@ARGV);
038 } else {
039 stream_files();
040 }
041
042 ###########################################
043 sub search {
044 ###########################################
045 my $term = join " ", @_;
046
047 my $swish = SWISH::API->new($IDX_FILE);
048
049 $swish->AbortLastError
050 if $swish->Error;
051
052 my $results = $swish->Query(
053 join ' ', @ARGV);
054
055 $swish->AbortLastError
056 if $swish->Error;
057
058 my $hits = $results->Hits;
059 if ( !$hits ) {
060 print "No Results\n";
061 return;
062 }
063
064 my @results = ();
065 my @select = ();
066 my %map = ();
067
068 while (my $r = $results->NextResult) {
069 push @results, $r;
070 my $path = my $org_path =
071 $r->Property( "swishdocpath");
072 $path =~ s|^$_/|| for @DIRS;
073 push @select, $path;
074 $map{$path} = $org_path;
075 }
076
077 our($Eof, $Reply);
078 @select = sort @select;
079
080 select my $file (@select) {
081 system "$LESS $map{$file}";
082 last;
083 }
084 }
085
086 ###########################################
087 sub stream_files {
088 ###########################################
089 my $rule = File::Find::Rule
090 ->file()
091 ->name('*.pod', '*.pm')
092 ->start(@DIRS);
093
094 while(my $file = $rule->match()) {
095 print STDERR "Processing $file\n";
096 my $parser =
097 Pod::Simple::TextContent->new();
098 my $output = "";
099 $parser->output_string(\$output);
100 $parser->parse_file($file);
101 my $size = length($output);
102
103 print STDERR "*** $file\n";
104 print "Path-Name: $file\n",
105 "Document-Type: TXT*\n",
106 "Content-Length: $size\n\n";
107 print $output;
108 #print $output;
109 }
110 }
111
112 ############################################
113 sub update_index {
114 ############################################
115 if(! -e $CNF_FILE) {
116 print "Creating $CNF_FILE\n";
117 mkpath(dirname($CNF_FILE));
118 open FILE, ">$CNF_FILE" or
119 die "Can't open $CNF_FILE ($!)";
120 print FILE "IndexDir $0\n",
121 "IndexFile $IDX_FILE\n",
122 "UseStemming Yes\n";
123 close FILE;
124 }
125 system("$SWISH -c $CNF_FILE -S prog");
126 }
Die SWISH-E-Distribution holt man von [2] als Tarball ab und
installiert sie wie üblich:
./configure
make install
Außerdem enthält sie das Perl-Modul SWISH::API gleich mit.
Einfach eine Stufe weiter hinuntersteigen und ebenfalls installieren:
cd perl
perl Makefile.PL
make install
Dann sind eventuell noch die Konfigurationsvariablen in den Zeilen 18 bis 24
in perldig an die lokalen
Gegebenheiten anzupassen und schon kann's losgehen: Als erstes
sollte man den Index generieren (u für update):
perldig -u
Dann kann die Suche losgehen:
perldig obfuscated
Bringt bei mir satte neun Treffer. Die Perl-Dokumentation birgt ungeahnte Schätze. Wühlen bildet!
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |