
Stetig hereintröpfelnde Daten müssen nicht zwangsläufig die Festplatte
auffüllen. Wenn eine Round-Robin-Datenbank wie rrdtool selektiv
unwichtige Details vergisst, bleibt das System bis zum
Sankt-Nimmerleins-Tag wartungsfrei.
Das von Tobias Oetiker entwickelte rrdtool, das mit sogenannten
Round-Robin-Datenbanken (RRDs) als Storage-Medium
arbeitet, hat sich zum quasi-Standard
bei der Speicherung von Netzwerk-Überwachungsdaten gemausert. Applikationen wie
Cacti [3] machen von der vergesslichen Datenbank heftigen Gebrauch.
Ein Round-Robin-Archiv (RRA) stellt man sich am Besten wie in Abbildung
1 dargestellt vor: Dort liegen auf einer begrenzten Anzahl von
Speicherplätzen die
von einem Monitorskript auf einem Webserver gefundenen Lastwerte:
Angefangen vom Wert 6.1 um 01:00:00
Uhr (oben Mitte), dann, weiter rechts im Kreis, der Wert 2.0 um 01:05:00,
undsofort, bis schließlich um 01:20:00 der Wert 2.4 gespeichert wurde. Der
Zeiger deutet auf den zuletzt aktualisierten Eintrag. Das
Ergebnis der nächsten Messung passt aber nicht mehr ins Archiv --
und deshalb wird, wie Abbildung 2 zeigt, der Wert von 01:00:00 Uhr mit dem
neuen Wert 4.1 um 01:25:00 Uhr überschrieben.
| |
| Abbildung 1: Das Round-Robin-Archiv hält eine feste Anzahl von Datenwerten vorrätig und überschreibt alte Werte, um Platz für neue zu schaffen. |
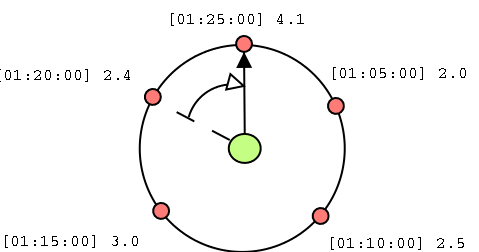 |
| Abbildung 2: Der alte, um 01:00:00 gemessene Wert wurde mit dem um 01:25:00 übermittelten ersetzt und der Zeiger weitergeführt. |
Nun ist der Admin aber nicht nur an Messwerten der letzten 25 Minuten interessiert, sondern möchte sicher auch einmal anzeigen, wie sich die Rechnerlast über die letzten dreißig Tage oder die zurückliegenden zwölf Monate entwickelt hat. Auch hierzu braucht man keine riesigen Datenmengen vorzuhalten, denn über größere Zeiträume hinweg akzeptiert man gerne eine geringere Granularität -- der Trick: Es werden einfach weitere RRAs angelegt, die die Durchschnittslast (oder die Höchstlast, ganz nach Geschmack) pro Stunde für den letzten Tag oder pro Tag für's laufende Jahr aufnehmen.
Sind diese Round-Robin-Archive einmal in der Datenbank angelegt, füttert
das als Kommandozeilen-Tool oder Perl-Schnittstelle erhältliche
rrdtool einfach transparent neue Messwerte hinein. Der darunterliegende
Datenbankmotor sorgt automatisch dafür, dass die Kreise mit den
verschiedenen Granularitäten die richtig aufpolierten Daten erhalten.
Spätere Abfragen liefern
dann die Werte über einen angegebenen Zeitraum in der höchsten verfügbaren
Genauigkeit und rrdtool zeichnet davon sogar formschöne Webgrafiken.
Die Definition einer Round-Robin-Datenbank besteht aus einer oder mehreren Datenquellen (DS (Data Sources)). Für jede einzelne gibt der RRD-Administrator beim Anlegen der Datenbank folgende Parameter an:
load
oder mem_usage), der die Eingabedatenquelle
eindeutig in der RRD identifiziert
einen Datenquellentyp (DST, Data Source Type), der zum
Beispiel festlegt, ob
die Eingabewerte einfach übernommen werden (GAUGE (sprich: ``Geydsch'')
oder von einem stetig
anwachsenden Zähler stammen, der Extra-Service beim Überlauf benötigt
(COUNTER).
die Breite des Eingabe-Zeitfensters (step). Purzeln während dieses
Zeitraums mehrere Messwerte herein, wird statt den Einzelwerten der
Mittelwert berechnet und abgespeichert. Kommt in diesem Intervall kein
einziger Wert daher, wird na (not available) abgelegt.
Minimale und maximale Eingangswerte. Liegen Messwerte daneben, werden
sie ignoriert.
Legen wir also mal eine Datenbank mit einer Eingabequelle names load an,
die alle 60 Sekunden Werte für die gerade anliegene Rechnerlast liefert:
use RRDs;
RRDs::create(
"/tmp/load.rrd", "--step=60",
"--start=" . time() - 10,
"DS:load:GAUGE:90:0:10.0",
"RRA:MAX:0.5:1:5",
"RRA:MAX:0.5:5:10");
Gaack! Wird Zeit, dass mal jemand ein intuitives OO-Interface für
RRDtool schreibt, bis es soweit ist, einige Erklärungen: In der
Datei /tmp/load.rrd wird rrdtool die Datenbank ablegen. Das vorgegebene
Eingabeintervall ist 60 Sekunden (--step=60), in diesen Zeitabständen
werden später die Daten eingefüttert. Die Startzeit der Datenbank
wird auf 10 Sekunden in der Vergangenheit gelegt. Das ist üblich (und
voreingestellt, wenn man --start weglässt), denn RRD wird alle
Eingaben zurückweisen, die einen Zeitstempel kleiner oder gleich der
Startzeit tragen. Die DS:-Zeile definiert die einzige Datenquelle
der Datenbank mit den oben beschriebenen Parametern: Quellenname
load, Eingabetyp GAUGE, Minimal- und Maximalwert
0 bzw. 10.0 und dem sogenannten Heartbeat von 90.
Diese mit 90 angegebene Pulsfrequenz legt fest, dass wir auch zufrieden
sind, falls die Daten nicht mit der in --step vorgeschriebenen Rate
(alle 60 Sekunden) ankommen, sondern mit bis zu 30 Sekunden Verzögerung.
RRDtool lügt dann und interpoliert einfach. Wäre -- als Extremfall --
der Heartbeat 24 Stunden und
die Schrittrate weiterhin 60, genügte ein einziger gefütterter Wert
pro Tag, auf den RRDtool dann alle Minuteneinträge setzen würde.
Andererseits kann ein schneller tickender Puls auch mehr Messdaten erfordern
als das Zeitfenster der Datenbank aufnehmen kann:
Dann erwartet rrdtool Dateneingaben
im Rhytmus des Herzens und speichert sofort streng
na für einen Schritt, falls der Herzschlag einmal aussetzt.
Liegen ordnungsgemäß mehrere Werte
pro Schrittfenster vor, mittelt RRD diese, bevor der sogenannte
Primary Data Point (PDP) abgespeichert wird.
Soweit zur Definition der (in diesem Fall einzigen) Datenquelle DS. Sie bestimmte die Transformation von Eingangsmesswerten zu Primary Data Points, dem Ausgangspunkt für die nun folgenden Round-Robin-Archive, die durch die Zeilen
"RRA:MAX:0.5:1:5",
"RRA:MAX:0.5:5:10"
definiert wurden.
Der Zahlenwert in der vorletzten Kolumne gibt jeweils an,
wieviele Primary Data Points das Archiv zu einem Archivpunkt zusammenfasst.
Das erste Archiv nimmt einen, entspricht also exakt dem in den Abbildungen
1 und 2 dargestellten Round-Robin-Archiven. Das zweite Archiv hingegen nimmt
fünf Messpunkte für einen Archiv-Punkt. Bei einem
einzigen PDP gibt's nichts zu entscheiden,
aber bei fünfen ist die zweite Kolumne der Definition oben
wichtig, welche die Consolidation Function (CF) angibt: AVERAGE nimmt
zum Beispiel den Mittelwert aus den PDPs, das oben verwendete MAX nimmt
den Höchstwert, MIN oder LAST wären andere Optionen. Die letzte Kolumne
bestimmt, wieviele Datenplätze das Archiv bereitstellt. Sind alle aufgefüllt,
beginnt es, die ältesten zu überschreiben. Und schließlich die magische
0.5: Dieser sogenannte xfiles factor bestimmt, welcher Bruchteil von den
PDPs undefiniert (na) sein darf, damit das Archiv einen interpolierten
Mittelwert als gültigen Eintrag einträgt. Wird der Wert unterschritten,
steht am Ende na im Archiv.
Abbildung 3 zeigt noch einmal, wie aus den Werten, die die Datenquelle liefert, PDPs werden, die anschließend in die verschiedenen Round-Robin-Archives wandern.
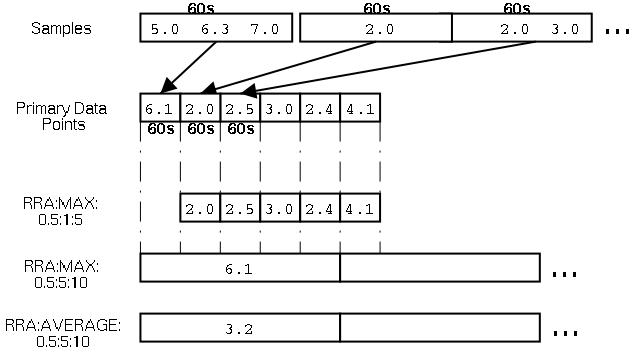 |
| Abbildung 3: Wie Sample-Werte zu Primary Data Points (PDPs) werden und daraus wiederum RRAs entstehen |
Listing rrdtest zeigt ein Testskript, das eine RRD definiert, fabrizierte
Daten hineinfüttert und dann die Archivdaten abfragt. Für reproduzierbare
Ergebnisse nutzt es statt der Systemzeit den Zeitstempel 1080460200.
(Geheimtipp: RRD fängt wild zu runden an, falls keine durch 60 (und für
das 5-Minuten-Archiv sogar 300) teilbare Zahl
verwendet wird. Das mittelt sich zwar auf Dauer, aber für
Demonstrationszwecke eignen sich glatte Werte besser).
Die Zeilen 17 bis 22 erzeugen die RRD, wie oben beschrieben. Die
for-Schleife ab Zeile 26 läuft von 0 bis 40 und schiebt mit
RRDs::update() die folgenden
Zeitstempel-Lastwert-Kombinationen als Strings in die RRD:
1080460200:2
1080460260:2.1
1080460320:2.2
...
Im Normalbetrieb kann man den Zeitstempel auch weglassen, dann nimmt
das RRDs-Modul
die aktuelle Systemzeit. Bei den übergebenen Werten handelt es sich
um künstlich erzeugte Beispielwerte für die Systemlast, das Testskript
startet einfach bei 2 und erhöht den Wert pro Schritt um 0.1.
Um ein Archiv abzufragen, nimmt
RRDs::fetch() das gewünschte Abfrageintervall mit der
beim Abspeichern verwendeten Consolidation Function (CF)
entgegen und ermittelt
daraus das Archiv mit der maximal verfügbaren Auflösung. Wurde
eine CF angegeben, für die kein Archiv existiert, hagelt's eine
Fehlermeldung. RRDs::fetch() gibt die
Datenpunkte des Archivs in $data zurück, einer Referenz auf einen
Array, der wiederum Referenzen enthält, die auf Arrays mit den
Floating-Point-Datenwerten zeigen.
Die außerdem von RRDs::fetch() zurückgelieferten Werte sind $dbstart
(Startzeitpunkt der RRD), $step (der Zeitabstand der Datenpunkte
im ausgewählten Archiv) und $names (eine Referenz auf einen Array
mit den Namen aller Datenquellen). $step ist übrigens nicht unbedingt
die mit --step eingestellten Datensammelabstand der Datenbank -- für
ein angegebenes Archiv, das eine Anzahl von PDPs zu einem Archivpunkt
zusammenfasst, ergibt sich $step aus der Multiplikation von Sammelabstand
und der Anzahl der pro Archivpunkt zusammengefassten Punkte.
Zeile 36 startet eine Abfrage im Zeitfenster der letzten fünf Minuten vor dem Ende und fördert folgendes zutage:
Last 5 minutes:
1080462300: N/A
1080462360: 5.6
1080462420: 5.7
1080462480: 5.8
1080462540: 5.9
1080462600: 6
Das Modul
RRDs hat hierzu das Kurzzeit-Archiv mit 60 Sekunden Datenabstand gewählt.
Da es immer nur fünf Werte vorhält, ist der älteste Wert na.
Fragt man, wie in Zeile 39,
die Funktion RRDs::fetch() hingegen nach Werten für ein
breiteres Fenster, wie zum Beispiel die
letzten 30 Minuten der Messreihe, enthält das Ergebnis Werte aus
dem zweiten Archiv, das die Daten im 300-Sekunden-Abstand speichert:
Last 30 minutes:
1080460800: 3
1080461100: 3.5
1080461400: 4
1080461700: 4.5
1080462000: 5
1080462300: 5.5
1080462600: 6
Bei den eingetragenen Werten handelt es sich um im jeweiligen
Intervall gemessenen Höchstwert, da das zweite Archiv mit der CF MAX
definiert wurde.
Das Modul
RRDs wird übrigens nicht versuchen, Werte aus einer Kombination
von Archiven darzustellen: Es wählt ein passendes Archiv aus
und nutzt dessen Granularität für eine Ergebnisreihe mit konstanten
Zeitabständen.
01 #!/usr/bin/perl
02 ###########################################
03 # Feed test data to RRD
04 # Mike Schilli, 2004 (m@perlmeister.com)
05 ###########################################
06 use warnings;
07 use strict;
08
09 use RRDs;
10
11 my $DB = "/tmp/mydemo.rrd";
12 my $start = 1080460200;
13 my $dst = "MAX";
14 my $nof_iterations = 40;
15 my $end = $start + $nof_iterations * 60;
16
17 RRDs::create(
18 $DB, "--step=60",
19 "--start=" . ($start-10),
20 "DS:load:GAUGE:90:0:10.0",
21 "RRA:$dst:0.5:1:5",
22 "RRA:$dst:0.5:5:10",
23 ) or
24 die "Cannot create rrd ($RRDs::error)";
25
26 for(0..$nof_iterations) {
27 my $time = $start + $_ * 60;
28 my $value = 2 + $_ * 0.1;
29
30 RRDs::update(
31 $DB, "$time:$value") or
32 die "Cannot update rrd ($!)";
33 }
34
35 print "Last 5 minutes:\n";
36 fetch($end - 5*60, $end, $dst);
37
38 print "Last 30 minutes:\n";
39 fetch($end - 30*60, $end, $dst);
40
41 ###########################################
42 sub fetch {
43 ###########################################
44 my($start, $end, $dst) = @_;
45
46 my ($dbstart, $step, $names, $data) =
47 RRDs::fetch($DB, "--start=$start",
48 "--end=$end", $dst);
49
50 foreach my $line (@$data) {
51 print "$start: ";
52 $start += $step;
53 foreach my $val (@$line) {
54 $val = "N/A" unless defined $val;
55 print "$val\n";
56 }
57 }
58 }
Nun aber, nachdem diese Ausführungen hoffentlich etwas Licht in den
dunklen Keller von RRDtool geworfen haben, zu einer praktischen
Anwendung: Das Skript in Listing rrdload läuft per cronjob einmal alle fünf
Minuten:
*/5 * * * * /home/mschilli/bin/rrdload -u
Mit der Option -u aufgerufen, frischt es ein Round-Robin-Archiv mit dem
Messwert der aktuellen Systemlast auf und verabschiedet sich dann wortlos.
Zur graphischen Auswertung wird es als
rrdload -g
aufgerufen. Es legt dann eine formschöne Grafik (wie in Abbildung 4 gezeigt) als PNG-Datei im Dokumentenpfad des Webservers ab. Lade ich dieses Bild im Browser, kann ich auf perlmeister.com kontrollieren, wie sich die Systemlast auf diesem Shared-System über die Zeit entwickelt. Abbildung 4 zeigt das Ergebnis.
C<rrdload> legt ab Zeile 21 drei Archive an: Das erste nimmt 12*24 = 288 Datenpunkte auf, stellt also genügend Plätze bereit, um die alle fünf Minuten ermittelten Werte einen Tag lang zu speichern. Das zweite Archiv sucht die Spitze aus zwölf Messpunkten, also eine Stunde (12*5min = 60min) lang einrieselnde Daten, und speichert 24*7 = 168 davon. Also steht später die jeweils letzte Woche im Stundentakt zur Abfrage bereit. Das dritte und letzte Archiv findet die Tagesspitzen und hält 365 davon für die Jahresbilanz vorrätig.
Die erzeugte Grafik im PNG-Format wird mit RRDs::graph() erzeugt
und erhält mit --vertical-label noch eine Beschriftung für
die Lastachse. Die beiden Argumente
"DEF:myload=$DB:load:MAX",
"LINE2:myload#FF0000")
bestimmen, dass das RRDs-Modul aus der angegebenen Datei (in $DB)
Ergebnisdaten bezieht und diese der Graphenvariable myload zuordnet.
Es werden Werte der Datenquelle load gesucht, in einem Archiv, das
zum vorher angegebenen Zeitraum (--start bis --end) Daten mit
der Consolidation Function MAX gewonnen hat. rrdtool hat die
zweifelhafte Angewohnheit, die Datenbank am Anfang zufällig zu füllen
und über die Startzeit eine falsche Auskunft zu geben -- deswegen
greift die ab Zeile 46 definierten Funktion rrd_start_time
hinein
und holt solange Daten heraus, bis etwas vernünftiges hervorkommt.
Das Datum diese Messwerts gibt sie dann zurück,
und die graph-Funktion nimmt es entgegen.
Das verwendete RRDs::fetch geht ohne Angabe einer
Startzeit genau einen Tag zurück,
wer mehr im Graphen sehen möchte, kann mit --start einen anderen
Zeitpunkt bestimmen. Negative Werte setzen
relative Zeitdifferenzen zur gegenwärtigen Uhrzeit, mit
"--start", -365*24*3600
werden immer alle verfügbaren Daten (allerdings in der gröbsten Auflösung) im Graphen angezeigt.
Den Graphen malt sie elegant ganz in Rot (#FF0000),
und wegen LINE2 genau zwei Pixel stark.
 |
| Abbildung 4: Die Last auf perlmeister.com über eine Nacht. |
01 #!/usr/bin/perl
02 ###########################################
03 # rrdload -- Measure CPU load over time
04 # Mike Schilli, 2004 (m@perlmeister.com)
05 ###########################################
06 use warnings;
07 use strict;
08
09 use RRDs;
10 use Getopt::Std;
11
12 getopts("ug", \my %opts);
13
14 my $DB = "/tmp/load.rrd";
15 my $SERVER = "/www/htdocs";
16 my $UPTIME = "uptime";
17
18 if(! -f $DB) {
19 RRDs::create($DB, "--step=300",
20 "DS:load:GAUGE:330:U:U",
21 "RRA:MAX:0.5:1:288",
22 "RRA:MAX:0.5:12:168",
23 "RRA:MAX:0.5:288:365",
24 ) or die "Create error: ($RRDs::error)";
25 }
26
27 if(exists $opts{u}) {
28 my $uptime = `$UPTIME`;
29 my ($load) = ($uptime =~ /(\d\.\d+)/);
30
31 RRDs::update($DB, time() . ":$load") or
32 die "Update error: ($RRDs::error)";
33 }
34
35 if(exists $opts{g}) {
36 RRDs::graph("$SERVER/load.png",
37 "--vertical-label=Load perlmeister.com",
38 "--start=" . rrd_start_time(),
39 "--end=" . time(),
40 "DEF:myload=$DB:load:MAX",
41 "LINE2:myload#FF0000") or
42 die "graph failed ($RRDs::error)";
43 }
44
45 ###########################################
46 sub rrd_start_time {
47 ###########################################
48
49 my ($start,$step,$names,$data) =
50 RRDs::fetch($DB, "MAX");
51
52 foreach my $line (@$data) {
53 if(! defined $line->[0]) {
54 $start += $step;
55 next;
56 }
57 return $start;
58 }
59 }
Das Perl-Modul RRDs, das eine Shared Library von RRDtool nutzt,
gibt's nicht auf dem CPAN, sondern es liegt der
RRD-Distribution bei. Um es zu installieren, lädt und entpackt man
den neuesten Source-Tarball (rrdtool-1.0.46.tar.gz) von [2] und
compiliert ihn mittels
./configure
make
Im Unterverzeichnis perl-shared findet sich dann die Distribution von
RRDs.pm, die wie üblich mit
perl Makefile.PL
make install
installiert wird. Überwacht auch ihr euren Provider!
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |