
OpenOffice hilft mit einer Vielzahl vorkonfigurierter Formate beim Ausdrucken von selbstklebenden Etiketten. Perl speist die dazu erforderlichen Adressdaten ins Dokument ein.
Wer noch altmodisch Glückwunschkarten mit der Hand schreibt und als Brief verschickt, hat vielleicht schon einmal damit geliebäugelt, sich das Adressenschreiben zu sparen und auf selbstklebende Etiketten umzustellen. Die praktischen lasertauglichen Abziehetiketten auf A4-Papier (zum Beispiel Abbildung 1) kosten etwa halben Cent pro Stück (15c pro Blatt) und helfen nicht nur beim antiquierten Snail-Mail-Versand, sondern eignen sich auch zum Beschriften von Netzgeräten und Kabeln. Das heute vorgestellte Perlskript liest kommaseparierte Texte ein und druckt sie zeilenweise auf die Labels. Es druckt also nicht nur Empfängeradressen, wie wär's zum Beispiel damit, mal den Kabelverhau unterm Schreibtisch zu beschriften, damit der gestresste Home-Admin das Router-Netzteil beim nächsten Mal auch sofort findet?
| |
| Abbildung 1: Lasertaugliche Etiketten, 30 pro Blatt, 4,200 pro Karton. |
Der OpenOffice Writer kennt bereits von Haus aus die Etikettenmaße vieler Hersteller und erzeugt über das Menü New->Labels (Abbildung 2) entsprechende tabellenartige Dokumente. Der User muss im Dialog in Abbildung 2 dazu lediglich den Hersteller und den Produktcode der verwendeten Etiketten eingeben, schon stimmen die Maße. Die so frisch angelegten Dokumente befüllt der User nur noch mit Textdaten und klickt auf "Drucken" -- viel einfacher, als selbst ein Programm zur Druckerpositionierung zu schreiben. Und da OpenOffice seine Dokumente im offenen ODF-Format ablegt, ist es ein leichtes, die Tabellendaten mittels eines selbstgestrickten Perlskripts aus einer CSV-Datei lesen und ins Dokument einzustreuen.
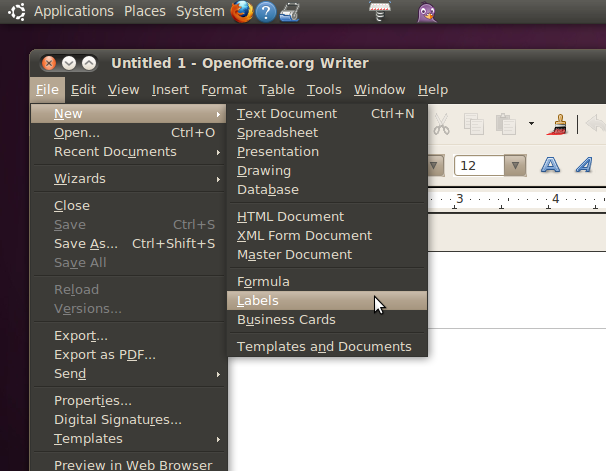 |
| Abbildung 2: Im Openoffice-Writer öffnet der Labels-Eintrag aus dem File/New-Menü eine reiche Auswahl von Aufkleber-Formaten. |
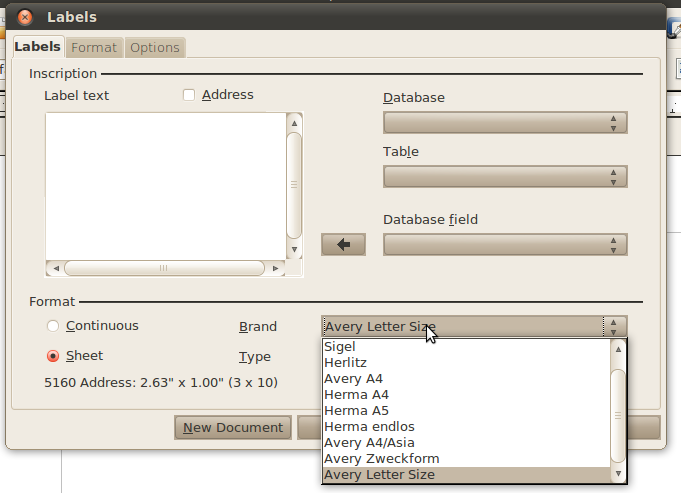 |
| Abbildung 3: Neben dem Aufkleberhersteller erlaubt der Dialog auch die Auswahl der Produktnummer. |
Vor dem automatisierten Einspeichern der Adressen erstellt der User manuell mit
OpenOffice einmalig ein Testdokument als
Vorlage und tippt einige Teststrings in die ersten vier Felder ein
(Abbildung 4). Das anschließend als
template.odt abgespeicherte Dokument
besteht, wie das
unzip-Kommando in Abbildung 5 zeigt, aus einem ZIP-Archiv mit etlichen
XML-Dateien, deren interessanteste content.xml mit dem mittels einer
XML-Markupsprache ausgezeichneten Textinhalt des Dokuments ist.
 |
| Abbildung 4: Der User tippt Beispieltexte in die Tabellenfelder des OpenOffice-Dokuments ein. |
 |
| Abbildung 5: Ein unzip-Aufruf fördert die XML-Dateien des OpenOffice-Dokuments zutage. |
Was nun dort steht und in welchen Markup-Strukturen die vom User
vorher in die Tabellenelemente eingegebenen Strings gelandet sind, zeigt der
Aufruf des Skripts in Listing 1 mittels oo-dumper template.odt.
Es nutzt das CPAN-Modul OpenOffice::OODoc und ruft dessen Konstruktor
ooDocument() mit dem Namen der zu untersuchenden Datei auf.
Als member legt Zeile 11 "content" fest, zeigt sich also am
Dokumenteninhalt interessiert und nicht an ausgelagerten Kopf- oder
Fußzeilen, wiederverwertbaren Style-Definitionen oder Meta-Informationen.
Die Methode selectElements setzt einen XPath-Query ab, der
alle XML-Elemente unterhalb des Tags office:body, also dem eigentlichen
Textdokument, zu Tage fördert. Dokumente enthalten nur einen einzigen
Body, allerdings besteht OpenOffice::OODoc darauf, dass die linke
Seite der Zuweisung in Zeile 14 einen List-Kontext suggeriert, deshalb
die einschließenden Klammern um $element. Zurück kommt eine Referenz
auf ein Objekt vom Typ OpenOffice::OODoc::Element, das aber aufgrund
von Vererbung auch die Methoden des ausführenden XML-Parsers
XML::Twig versteht. Dieses schon einmal in einem früheren Snapshot
vorgestellte ([3]), etwas eigenwillige XML-Modul stellt die Methode
_dump() bereit, die eine textuelle Aufbereitung eines XML-Unterbaums
generiert und als String zurückliefert.
01 #!/usr/local/bin/perl -w
02 use strict;
03 use OpenOffice::OODoc;
04
05 (my $file) = @ARGV;
06
07 die "usage: $0 file" unless defined $file;
08
09 my $doc = ooDocument(
10 file => $file,
11 member => "content",
12 );
13
14 (my $element) = $doc->selectElements(
15 '//office:body');
16
17 print $element->_dump();
 |
| Abbildung 6: Die _dump-Methode zeigt die Verschachtelung des XML-Dokuments. |
So zeigt sich in Abbildung 6, dass im Dokument unter dem Tag
office:body ein Tag namens office:text hängt, das nach einigen
Sequence-Deklarationen wiederum einen Textabsatz vom Typ text:p (Paragraph)
enthält. Dieser stellt sich als eine Tabellenzeile mit drei Spalten
heraus, für deren Rahmen jeweils Elemente vom Typ draw:frame
verantwortlich zeichnen, die wiederum ein draw:text-box-Element mit
einem text:p-Element enthalten, in denen sich endlich
die eingegebenen Testtexte ("test1", ...) wiederfinden.
Somit fördert ein XPath-Query vom Format
//office:body/office:text/text:p
alle Tabellenzeilen zutage (die ihrerseits wieder Spaltenrahmen enthalten), während sich die Tabellenelemente (drei pro Zeile) relativ dazu unter
.../draw:frame/draw:text-box/text:p
finden. Das Skript in Listing 2 bedient sich des ersten XPath-Queries, um erstmal das Dokument um soviele Tabellenzeilen zu erweitern, dass alle auszudruckenden Adressdaten darin Platz finden. Mit dem zweiten Query stöbert es dann durch alle Labels und pfercht jeweils die dafür bestimmten Textdaten hinein.
Zum Öffnen der .odt-Datei bedient es sich wieder des Konstruktors
ooDocument() auf die Datei ready.odt, die die Funktion cp
aus dem Modul Sysadm::Install in Zeile 21 vorher aus dem
Template template.odt erzeugt hat.
Die gegenwärtige Version von OpenOffice::OODoc weist einen Bug auf,
der sie UTF8-kodierte Daten inkorrekt verarbeiten lässt, falls diese
Umlaute enthalten. Die gewählte Einstellung
local_encoding =>> ""> behebt das Problem vorläufig, sollte aber
eigentlich auf den Wert "utf8" gesetzt sein.
Die Rohdaten legt der User in der Datei address-book.csv (Abbildung 7)
ab, von wo sie das Skript label-writer mit dem CPAN-Modul
Text::CSV_XS zeilenweise mit getline() ausliest.
Die ab Zeile 60 definierte Funktion addresses_scan öffnet dazu die
Datei mit dem Pragma :encoding(utf8), damit Perl dort stehende und in
UTF-8 kodierte Umlaute auch korrekt einliest und intern in den dafür
vorgesehenen Datenstrukturen das UTF-8-Flag setzt.
Die Variable $row zeigt
auf ein Array, dessen Elemente die in der CSV-Datei durch Kommata
getrennten Zeileneinträge repräsentieren. Um auf der linken Seite des
Labels, auf dem der Texteintrag später landet, etwas Platz zu lassen,
fügt das Ersetzungskommando in der for-Schleife ab Zeile 77 vor jeder
Labelzeile ein Leerzeichen ein. Zeile 82 fügt die Adresszeilen zu einem
String mit Zeilenumbrüchen zusammen und schiebt ihn ans Ende des
Arrays @addresses, den die Funktion nach getaner Arbeit ans
Hauptprogramm zurückreicht.
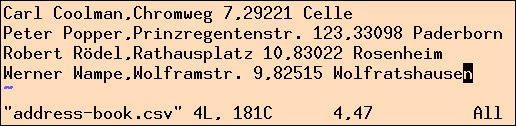 |
| Abbildung 7: Adressdaten im CSV-Format. |
01 #!/usr/local/bin/perl -w
02 use strict;
03 use OpenOffice::OODoc;
04 use Sysadm::Install qw( :all );
05 use Text::CSV_XS;
06 use POSIX qw(ceil);
07
08 my $template = "template.odt";
09 my $file = "ready.odt";
10 my $addr_book = "address-book.csv";
11 my $labels_per_page = 30;
12
13 my @addresses =
14 addresses_scan( $addr_book);
15
16 my $addtl_pages =
17 ceil( scalar @addresses /
18 $labels_per_page ) - 1;
19
20 # Put template in place
21 cp $template, $file;
22
23 my $doc = ooDocument(
24 file => $file,
25 type => "content",
26 local_encoding => "",
27 );
28
29 # Extend document as necessary
30 my @rows = $doc->selectElements(
31 '//office:body/office:text/text:p'
32 );
33
34 for ( 1 .. $addtl_pages ) {
35 for my $row ( @rows ) {
36 $doc->replicateElement( $row, "body" );
37 }
38 }
39
40 # All labels, including new ones
41 my @labels = $doc->selectElements(
42 '//office:body/office:text/text:p/' .
43 'draw:frame/draw:text-box/text:p'
44 );
45
46 my $addr_idx = 0;
47
48 for my $label ( @labels ) {
49 $doc->setStyle( $label, "P1" );
50 $doc->setText( $label,
51 $addresses[ $addr_idx ] );
52 $addr_idx++;
53 $addr_idx = 0 if
54 $addr_idx > $#addresses;
55 }
56
57 $doc->save();
58
59 ###########################################
60 sub addresses_scan {
61 ###########################################
62 my( $addr_book ) = @_;
63
64 my @addresses = ();
65
66 open( my $fh, "<:encoding(utf8)",
67 $addr_book ) or die "$addr_book: $!";
68
69 my $csv = Text::CSV_XS->new (
70 { binary => 1 } ) or die
71 "Cannot use CSV: " .
72 Text::CSV->error_diag ();
73
74 while( my $row = $csv->getline( $fh ) ) {
75 unshift @$row, "";
76
77 for ( @$row ) {
78 s/^/ /;
79 }
80
81 push @addresses,
82 join( "\n", @$row );
83 }
84 close $fh;
85
86 return @addresses;
87 }
Um nicht unnötig Etiketten zu verschwenden, füllt das Skript eine A4-Seite immer vollständig aus, notfalls durch Wiederholen der Adressen in der CSV-Datei. Andererseits muss Listing 2 bei einer Adressdatenbank, die mehr als 30 Einträge hat, zusätzliche Seiten am Ende des Dokuments einfügen. Auch in diesem Fall füllt es eine am Ende eventuell nicht ganz gefüllte Seite mit wiederholten Daten.
Zeile 16 ermittelt aus der Zahl der Adressen in der CSV-Datei und der
vordefinierten Anzahl von Labels pro Seite die notwendige Seitenzahl
des Etikettendokuments. Die Funktion ceil() aus dem POSIX-Modul
rundet bei gebrochenen Werten auf die nächste ganze Zahl auf. Die
Anzahl der zusätzlich gebrauchten Seiten in $addtl_pages ist dann
um Eins kleiner, da das Template-Dokument bereits vom User mit einer Seite
angelegt wurde.
Alle Tabellenzeilen der Testseite liegen nach dem ersten
X-Path-Query in Zeile 30 im Array @rows und für jede zusätzlich
zu generierende Seite iteriert die for-Schleife ab Zeile 35 über
diese Zeileneinträge, dupliziert sie mit replicateElement() und
weist die Funktion mit dem Parameter "body" an, die Dublette am Ende
des Dokumentkörpers einzufügen. Die neu erzeugten Zeilen sind exakte
Kopien der Zeilen der ersten Seite, enthalten also auch teilweise
Elemente mit Testdaten oder sind schlicht leer.
 |
| Abbildung 8: Nach dem Skriptlauf enthält die OpenOffice-Datei ready.odt alle eingefügten Adressen. |
Der zweite X-Path-Query in Zeile 41 fördert alle Tabellenelemente
(drei pro Zeile, inklusive aller Elemente auf neu erzeugten Seiten)
des Dokuments hervor und legt sie im Array @labels
ab. Die for-Schleife ab Zeile 48 klappert sie ab und weist ihnen den
Style "P1" zu. Der Dump in Abbildung 6 zeigt, dass dies daher rührt,
dass der User vorher beim Eingeben der Testdaten den Verana-Font eingestellt
hat. Der anschließende Aufruf von setText() nimmt den nächsten
Datensatz aus der Adressdatei und legt den zugehörigen Textstring
im gerade bearbeiteten Tabellenelements ab.
Die Schleife zählt die Indexvariable $addr_idx
des Adress-Arrays von Null ausgehend stetig hoch und setzt sie auf
Null zurück, falls sie das Ende der Adressdatenbank erreicht, um
wieder mit der ersten Adresse zu beginnen.
Die abschließend ausgeführte
Methode save() auf das Dokument sichert die bislang nur im
flüchtigen Speicher ausgeführten Veränderungen in der Zieldatei
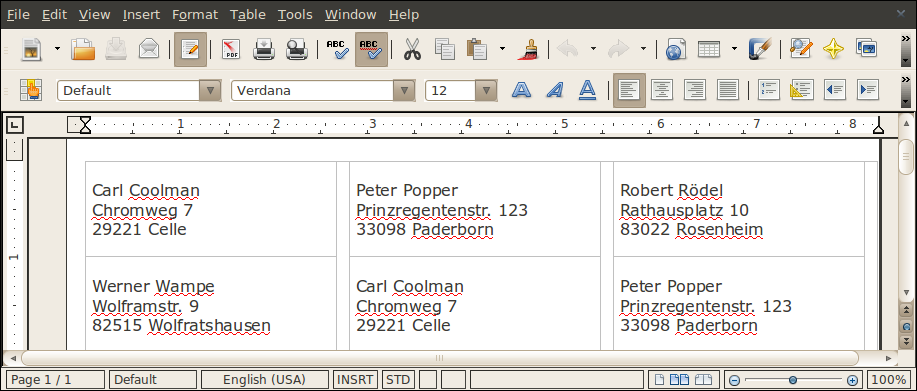
ready.odt auf der Festplatte. Ruft der User sie mit Openoffice
(getestet wurde mit Version 3.2) auf, zeigt sich das Dokument wie
in Abbildung 8. Nun gilt es nur noch, eine Seite mit
den Selbstklebeetiketten in den Drucker einzulegen und
in OpenOffice Writer den Menüeintrag "Print" anzuklicken. Um keine
Etiketten zu verschwenden, empfiehlt sich ein Probelauf mit einem
Blatt Papier, dessen Aufdruck man anschließend durch ein frisches
Etikettenblatt durchscheinen lässt. Ob die Etiketten im Papiereinzug nach
oben oder unten zeigen müssen, damit der Drucker sie richtig bedruckt,
und in welcher Richtung der Drucker das Blatt einziehen muss, lässt sich
am besten dadurch herausfinden, dass man ein Blatt Papier im Einzug an einer
Ecke mit Bleistift markiert, die Lage der Markierung auf dem Endergebnis
begutachtet und im Kopf komplizierte geometrische Transformationen
anstellt.
 |
| Abbildung 9: Die fertig gedruckten Etiketten. |
Zur Installation sind die Module OpenOffice::OODoc, Sysadm::Install und Text::CSV_XS notwendig, letzteres ist eine geschwindigkeitsoptimierte Version des Oldtimers Text::CSV. Eine CPAN-Shell installiert sie, falls sie in der verwendeten Distribution nicht schon verfügbar sind. Anschließend öffnet der User die Applikation OpenOffice Writer und wählt im Labels-Dialog das verwendete Etikettenformat aus. Der in Zeile 11 von Listing 2 voreingestellte Wert von 30 Labels pro Zeile ist an das verwendete Etikettenformat anzupassen.
Falls etwas nicht stimmt, hilft die Analyse der ODF-Datei mit
oo-dumper, um eventuelle Abweichungen vom Format durch
passende XPath-Queries zu kompensieren.
Nach dem Ausfüllen einiger Testfelder speichert
er die Datei als template.odt ab. Das Skript label-writer sollte
dann mit einer ordnungsgemäß in UTF-8 kodierten Adressdatei
address-book.csv ohne Ausgabe durchlaufen und die Datei read.odt
erzeugen, die der User dann an den Printer schickt.
Offensichtlich bieten sich weitere Anwendungsmöglichkeiten an: Kabelbeschriftungen wie im Rechenzentrum, oder auch Gerätenummern fürs Assett-Management. Vielleicht setze ich mir ja auch mein Buchhalter-Käppi auf, streife die Ärmelschoner über und verpasse jedem Buch meiner Privatbibliothek ein Etikett, das festlegt, in welches Regal es gehört ([5]).
Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2011/05/Perl
"A Simple Way to Do Labels in OpenOffice Writer", Solveig Haugland, http://openoffice.blogs.com/openoffice/2007/06/a-simple-way-to.html
"Datenfischer", Michael Schilli, Linux-Magazin 08/2005, http://www.linux-magazin.de/Heft-Abo/Ausgaben/2005/08/Datenfischer2
"The Perl OpenDocument Connector", Jean-Marie Gouarné, The Perl Review, tpr-200604-v3i1.pdf
"Ab die Post!", Michael Schilli, Linux-Magazin 10/2004, http://www.linux-magazin.de/Heft-Abo/Ausgaben/2004/10/Ab-die-Post
"Kein Etikettenschwindel", Michael Schilli, Linux-Magazin 2008/10, http://www.linux-magazin.de/Heft-Abo/Ausgaben/2008/10/Kein-Etikettenschwindel
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |